
 sign in
sign in
 join
join
Chromium Edge의 메모리 힙 스냅샷 분석을 위한 V8 엔진의 이해 2.
본문의 주제를 처음 준비하던 2018년 후반만 해도 본문은 'IE11을 이용한 JavaScript 디버깅' 시리즈의 일부분으로 구성되어 몇 편에 걸쳐 나뉘어 제공될 예정이었습니다. 그러나 공교롭게도 거의 동일한 시기에 Microsoft가 Chromium Edge에 대한 구체적인 계획을 발표함으로써 시리즈 자체의 필요성이 크게 줄어들었고, 결과적으로 다루고자 계획했던 내용을 끝까지 진행하지 못한 체 시리즈는 사실상 중단된 상태입니다.
비록 'IE11을 이용한 JavaScript 디버깅' 시리즈의 내용이 IE11의 F12 개발자 도구를 활용하는 방법에 중점을 두고 있기는 하지만, 최종 목표는 단순히 그에 그치지 않고 상대적으로 UI 및 기능이 단순한 IE11의 F12 개발자 도구에 친숙해진 다음, 거의 동일한 UI와 기능을 제공하지만 대폭 개선된 Classic Edge를 다루고, 또다시 보다 풍부한 기능을 제공하는 Chrome 등의 최신 브라우저로 접근을 확대해나가는 것이었습니다. 그러나 중간 징검다리 역할을 해줄 Classic Edge의 존재 위치가 불확실해짐에 따라 시리즈의 전반적인 맥락이 끊어졌다는 판단이었습니다.
드디어 2020년 초인 현재, 정식으로 배포되기 시작한 Microsoft의 Chromium Edge는 나름대로 순조롭게 시장에 안착하고 있는 것으로 보입니다. F12 개발자 도구라는 관점에서만 본다면 Chrome과 거의 동일한 UI 및 기능을 제공하고 있어서 기본적인 수준에서는 둘 중 어떤 브라우저를 선택하더라도 별다른 차이가 없을 듯합니다. 개인적으로 과거 IE11/Classic Edge 계열과 Chrome 계열로 나눴던 F12 개발자 도구 그룹을 이제는 IE11 계열과 Chromium Edge/Chrome 계열로 분류해도 무방할 것 같습니다. (FireFox까지 다루고 싶은 욕심도 있었지만 현실적으로 제 역량으로는 무리라고 생각되어 본문에서는 다루지 않습니다.)
본문에서는 IE11과 Chromium Edge의 F12 개발자 도구를 활용한 메모리 힙 스냅샷의 비교/분석을 통해 웹 브라우저의 메모리 누수를 감지하는 가장 기본적인 방법을 살펴봅니다.
시리즈 목차
- IE11 및 Chromium Edge에서 메모리 힙 스냅샷 찍기: 메모리 힙 스냅샷 찍기, 용어 및 기본적인 화면 구성 이해
- IE11 및 Chromium Edge에서 메모리 힙 스냅샷 비교하기: 메모리 힙 스냅샷 간 비교/분석 방법, 분리된 DOM 트리 검토 및 실습
- Chromium Edge의 메모리 힙 스냅샷 분석을 위한 V8 엔진의 이해 1: V8 엔진 실행 파이프라인, 인라이닝, 히든 클래스, 인라인 캐싱, 추적 로그 검토 방법
- Chromium Edge의 메모리 힙 스냅샷 분석을 위한 V8 엔진의 이해 2: 동일한 히든 클래스를 유지하기 위한 다양한 조건, SMI, 명명된 속성, 정수 인덱스 속성
- Visual Studio Community로 V8 엔진 다운로드 및 빌드하고 간단히 살펴보기: V8 엔진 소스 다운로드 및 빌드, depot_tools 설치, 기초적인 D8 옵션 플래그
- IE11 및 Chromium Edge에서 가상의 메모리 누수 상황 재현 및 해결하기: 잘못된 jQuery 사용 패턴, 전역 jQuery 캐시, Performance 창, Allocation instrumentation on timeline 프로파일링
문서 목차
들어가기 전에
지난 글에서는 Chromium Edge가 제공하는 메모리 힙 스냅샷을 보다 잘 이해하기 위한 준비 단계의 일환으로 V8 엔진의 극히 간단한 구조 및 가장 기본적인 최적화 기법 세 가지, 즉 인라이닝, 히든 클래스, 인라인 캐싱에 관해서 짧게나마 살펴봤습니다. 그리고 V8 엔진의 특성을 효과적으로 활용하기 위해서 웹 클라이언트 개발자가 실질적으로 수행할 수 있는 가장 간단한 방법은 최대한 JavaScript 개체 간의 히든 클래스를 동일하게 유지하는 것이라는 사실도 알게 되었습니다.
따라서 본문에서는 먼저 JavaScript 개체 간의 히든 클래스를 동일하게 유지하기 위해서 알고 있어야 할 사항들을 메모리 힙 스냅샷의 관점에서 조금 더 구체적으로 살펴본 다음, 한 단계 더 깊숙하게 들어가서 V8 엔진이 내부적으로 JavaScript 개체의 속성을 어떤 범주로 분류하여 관리하는지 확인해보도록 하겠습니다. 다만 본문은 히든 클래스에 대한 기본적인 정보를 이미 이해하고 있다는 전제하에 내용을 진행합니다. 그러므로 만약 그렇지 않다면 이전 글이나 다음 링크의 문서들을 먼저 읽어보시는 것을 권해드립니다.
- V8의 히든 클래스 이야기 | LINE ENGINEERING
- 자바스크립트 엔진의 최적화 기법 (2) - Hidden class, Inline Caching | TOAST Meetup
- JavaScript engine fundamentals: Shapes and Inline Caches | Mathias Bynens
- How JavaScript works: inside the V8 engine + 5 tips on how to write optimized code | SessionStack Blog
- 자바스크립트는 어떻게 작동하는가: V8 엔진의 내부 + 최적화된 코드를 작성을 위한 다섯 가지 팁 | Huiseoul Engineering (위 문서의 개인 번역본)
이 중에서 개인적으로 가장 추천하는 문서는 비록 영문이기는 하지만 세 번째 문서인 JavaScript engine fundamentals: Shapes and Inline Caches입니다. 이 문서에는 히든 클래스를 이해하는데 필요한 모든 내용이 담겨 있습니다. 그러나 너무 세부적인 내용까지는 관심이 없고 단지 기본적인 이해를 돕기 위한 한글 문서를 원한다면 짧지만 친절한 V8의 히든 클래스 이야기를 권해 드립니다.
메모리 힙 스냅샷으로 히든 클래스 비교하기
개체 간에 동일한 히든 클래스를 유지하기 위한 가장 기본적인 전제 조건은 개체에 동일한 이름의 속성을 동일한 순서로 추가하는 것입니다. 이 조건은 히든 클래스를 언급하는 모든 문서에서 공통적으로 강조하고 있는 사항이기도 합니다. 조건 자체가 매우 간단하기 때문에 이해하기도 쉽고 처음 들어보면 실무에 어렵지 않게 적용할 수 있을 것처럼 생각됩니다. 그러나 모든 일이 항상 그렇듯 히든 클래스를 염두에 두고 직접 코드를 작성하다 보면 단지 머리 속의 생각만으로는 판단하기가 모호한 경우가 많습니다.
두 개체 간에 히든 클래스가 동일한지 여부를 간단하게 판별할 수 있는 방법이 있으면 좋겠지만,
아쉽게도 Node.js 등의 환경과는 달리 브라우저 환경에서는 그런 역할을 수행해주는 %HaveSameMap() 같은 V8 엔진의 네이티브 함수를 활용할 수 있는 방안이 따로 없습니다.
대신 Chromium 계열의 브라우저에서는 조금 번거롭기는 하지만 지난 글에서 살펴본 것처럼 메모리 힙 스냅샷을 활용하여 확인이 가능합니다.
동일한 속성을 동일한 순서로 추가한 개체 간의 비교
먼저 정말로 동일한 속성을 동일한 순서로 추가한 개체 간에 히든 클래스가 동일한지부터 확인해보도록 하겠습니다. 대부분 그렇다고 얘기만 들었지 실제로도 동일한지 직접 확인해본 분은 아마 그렇게 많지 않을 것입니다. 만약 이 전제 조건이 틀리다면 이후의 나머지 내용은 언급하나 마나 한 얘기들이기 때문에 어떤 면에서는 기본 전제 조건이 옳은지 확인하는 이번 단계가 가장 중요합니다.
다음은 테스트에 사용한 예제 코드입니다.
변수 이름을 밑줄(_)로 시작하는 이유는 단지 메모리 힙 스냅샷에서 개체를 손쉽게 찾기 위한 것일 뿐이므로 참고하시기 바랍니다.
// 동일한 속성을 동일한 순서로 추가한 개체 간의 비교 1.
var _person1 = {
firstName: "John",
lastName: "Doe"
};
var _person2 = {
firstName: "Jane",
lastName: "Doe"
};
다음은 메모리 힙 스냅샷의 결과를 비교하기 쉽게 편집한 모습을 보여줍니다.
지난 글에서 설명했던 것처럼 각 개체에 공통적으로 존재하는 map 필드가 바로 히든 클래스를 참조하는 필드입니다.
두 map 필드의 개체 ID 값을 비교해보면 전제 조건의 언급과 같이 두 개체의 히든 클래스가 동일함을 확인할 수 있습니다.
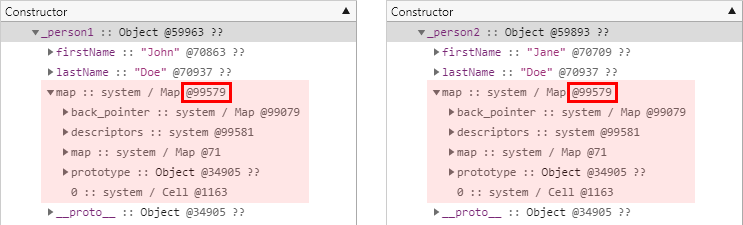
그렇다면 다음과 같이 개체 리터럴 내부의 속성 이름과 개수는 동일하지만 속성을 정의하는 코드 줄의 선후가 다른 경우에는 어떨까요?
...
var _person3 = {
lastName: "Smith", // 다음 줄과 순서가 바뀌었습니다.
firstName: "John"
};다음은 그 결과를 보여줍니다. 실제로 테스트를 해보기 전까지 어떤 결과를 예상하셨을지는 모르겠지만 결론은 참조하는 히든 클래스가 달라진다는 것입니다. 가만히 생각해보면 이는 매우 정상적인 결과라고 말할 수 있는데, 왜냐하면 각각의 속성이 추가되는 순서에 따라서 속성의 오프셋도 달라지기 때문입니다. 기존의 Full-codegen과는 달리 Ignition은 코드를 한 줄씩 해석하는 인터프리터 방식이라는 점을 기억해야만 합니다.
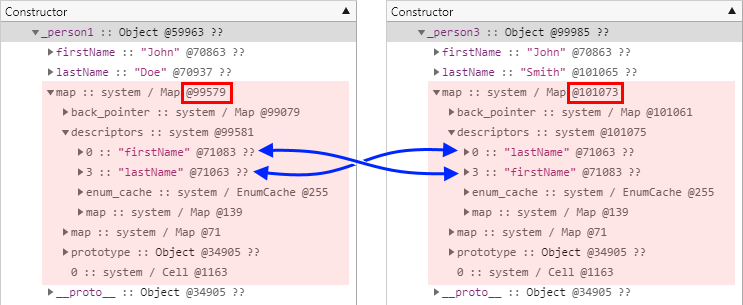
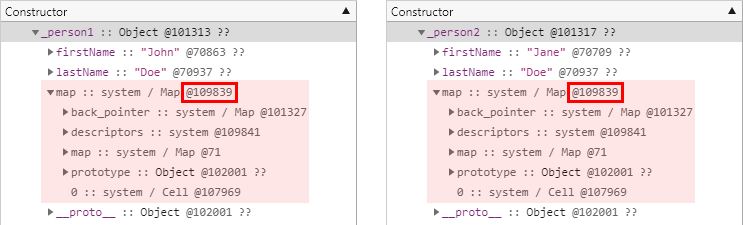
그렇다면 이번에는 빈 개체만 생성한 다음 동일한 순서로 속성들을 추가하여 비교해보도록 하겠습니다. 다음은 테스트에 사용한 예제 코드입니다.
// 동일한 속성을 동일한 순서로 추가한 개체 간의 비교 2.
var _person1 = {};
var _person2 = {};
_person1.firstName = "John";
_person1.lastName = "Doe";
_person2.firstName = "Jane";
_person2.lastName = "Doe";그리고 다음은 테스트 결과입니다. 역시 이번에도 두 개체가 동일한 히든 클래스를 참조하는 것을 확인할 수 있습니다.
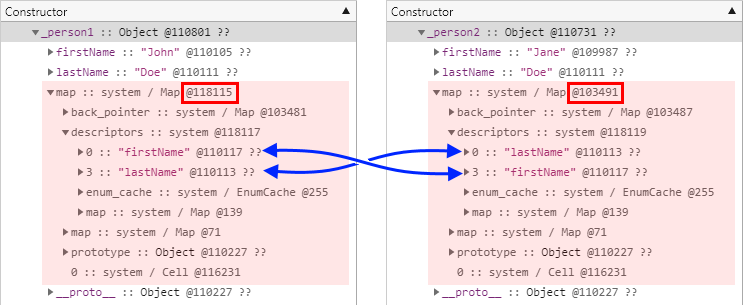
동일한 속성을 다른 순서로 추가한 개체 간의 비교
반대로 이번에는 동일한 속성을 다른 순서로 추가한 개체 간에 정말로 서로 다른 히든 클래스를 참조하는지 확인해보도록 하겠습니다. 다음은 테스트에 사용한 예제 코드입니다.
// 동일한 속성을 다른 순서로 추가한 개체 간의 비교
var _person1 = {};
var _person2 = {};
_person1.firstName = "John";
_person1.lastName = "Doe";
_person2.lastName = "Doe";
_person2.firstName = "Jane";그리고 다음은 테스트 결과입니다. 기대했던 바와 같이 두 개체가 서로 다른 히든 클래스를 참조하고 있음을 확인할 수 있습니다. 역시 이번에도 문제의 핵심은 속성 이름이 동일하더라도 추가된 순서가 다르면 속성의 오프셋이 달라진다는 점이라는 사실을 알 수 있습니다.
속성과 함께 선언된 개체 vs. 개체 선언 이후 속성이 추가된 개체
지금부터는 조금씩 더 미묘한 차이점을 바탕으로 생성된 개체 간의 히든 클래스를 비교해보도록 하겠습니다. 가령 이번에는 애초부터 속성과 함께 선언된 개체와 일단 빈 개체만 생성한 후 동일한 속성을 추가한 개체를 비교해봅니다. 물론 두 개체에 최종적으로 추가되는 속성 개수와 이름은 동일합니다. 다음은 테스트에 사용한 예제 코드입니다.
// 속성과 함께 선언된 개체 vs. 개체 선언 이후 속성이 추가된 개체
var _person1 = {
firstName: "John",
lastName: "Doe"
};
var _person2 = {};
_person2.firstName = "Jane";
_person2.lastName = "Doe";그리고 다음은 테스트 결과입니다. 역시 이번에도 두 개체가 서로 다른 히든 클래스를 참조하고 있음을 확인할 수 있습니다.
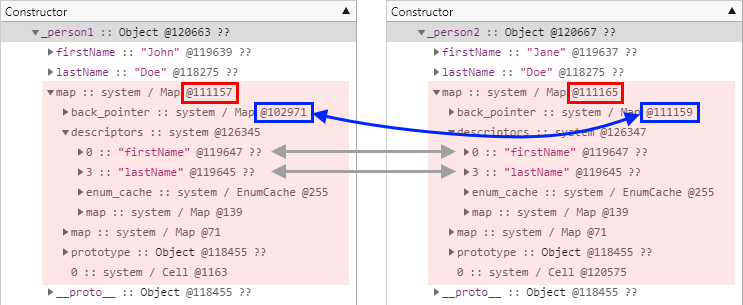
그런데 이번에는 그 결과의 양상이 조금 다릅니다.
이번 테스트 결과 역시 직전 테스트와 마찬가지로 서로 다른 히든 클래스를 참조하고 있기는 한데, 속성들의 오프셋은 모두 동일한 반면, 히든 클래스들 간의 전환 구조에 대한 정보를 담고 있는 전환 체인(Transition Chains) 상에서 현재 히든 클래스가 어떤 히든 클래스로부터 전환되었는지를 알려주는, back_pointer 필드가 서로 다른 개체를 참조하고 있습니다.
이 결과로 미루어 짐작할 수 있는 바는 V8 엔진이 개체를 생성하는 방식에 따라서 히든 클래스의 전환 구조를 생성하는 방식을 최적화 할 수 있을 만큼 유연하다는 사실입니다.
개체 리터럴 방식 vs. 생성자 함수 방식
계속해서 이번에는 개체 리터럴 방식으로 생성한 개체와 생성자 함수 방식으로 선언한 개체의 히든 클래스를 비교해봅니다. 다음은 테스트에 사용한 예제 코드입니다.
// 개체 리터럴 방식 vs. 생성자 함수 방식 1.
var _person1 = {
firstName: "John",
lastName: "Doe"
};
function _Person(firstName, lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
var _person2 = new _Person("Jane", "Doe");
그리고 다음은 테스트 결과입니다.
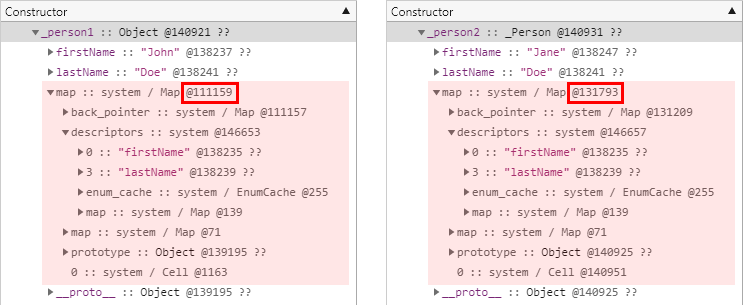
두 개체가 서로 다른 히든 클래스를 참조하고 있음을 확인할 수 있는데 근본적인 원인은 두 개체의 생성자가 다르기 때문입니다.
가령 개체 리터럴 방식으로 생성한 _person1 개체의 히든 클래스를 추적해서 올라가보면 생성자가 Object() 입니다.
반면 생성자 함수 방식으로 생성한 _person2 개체의 히든 클래스를 추적해서 올라가보면 당연한 얘기지만 생성자가 _Person() 입니다.
그렇다면 이번에는 똑같이 생성자 함수 방식으로 두 개체를 생성하되 속성의 정의 순서를 변경해보면 어떨까요? 다음의 예제 코드와 같이 말입니다.
// 개체 리터럴 방식 vs. 생성자 함수 방식 2.
function _PersonMale(firstName, lastName) {
this.gender = "Male";
this.firstName = firstName;
this.lastName = lastName;
}
function _PersonFemale(firstName, lastName) {
this.firstName = firstName;
this.lastName = lastName;
this.gender = "Female";
}
var _person1 = new _PersonMale("John", "Doe");
var _person2 = new _PersonFemale("Jane", "Doe");
코드가 다소 억지스럽기는 하지만 테스트 결과는 다음과 같습니다.
두 개체의 속성 오프셋이 다를 뿐만 아니라 생성자 역시 _PersonMale()과 _PersonFemale()로 각각 다르기 때문에 당연히 서로 다른 히든 클래스를 참조함을 확인할 수 있습니다.
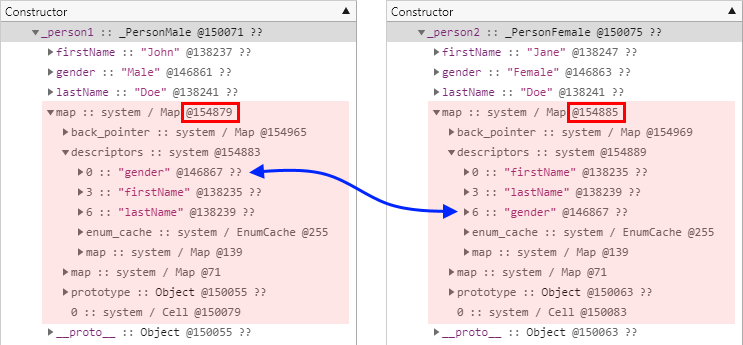
따라서 지금까지의 테스트 결과를 잠시 돌이켜보면 단지 개체에 동일한 이름의 속성을 동일한 순서로 추가하는 것만으로는 같은 히든 클래스를 유지할 수 없다는 사실을 알 수 있습니다. 개체 생성자가 같고 개체에 속성을 정의 또는 추가하는 방식과 순서, 그리고 이름까지 모두 동일해야만 합니다.
같은 이름의 다른 형식 속성을 가진 개체 간의 비교
그렇다면 속성의 이름과 정의 순서는 같지만 그 값의 형식이 다르다면 히든 클래스에도 영향이 미칠까요? 다음의 예제 코드와 같이 말입니다.
// 같은 이름의 다른 형식 속성을 가진 개체 간의 비교
var _person1 = {
firstName: "John",
lastName: "Doe",
age: "unknown" // 문자열 형식
};
var _person2 = {
firstName: "Jane",
lastName: "Doe",
age: 25 // SMI(Small Integer) 형식
};
var _person3 = {
firstName: "John",
lastName: "Smith",
age: 20.5 // Double 형식
};
var _person4 = {
firstName: "Jane",
lastName: "Smith",
age: null // null 형식
};다음은 테스트 결과입니다. 네 개체가 모두 동일한 히든 클래스를 참조하는 것을 확인할 수 있습니다. 이 자리에서 모든 형식의 속성을 테스트해 본 것은 아니지만 속성이 담고 있는 대부분의 값 형식은 히든 클래스에는 영향을 주지 않는 것으로 간주해도 큰 무리가 없을 듯합니다. 일부 특수한 형식에 대한 영향도가 궁금하다면 지금과 비슷한 방식으로 직접 간단하게 테스트해 보면 쉽게 답을 얻을 수 있을 것입니다.
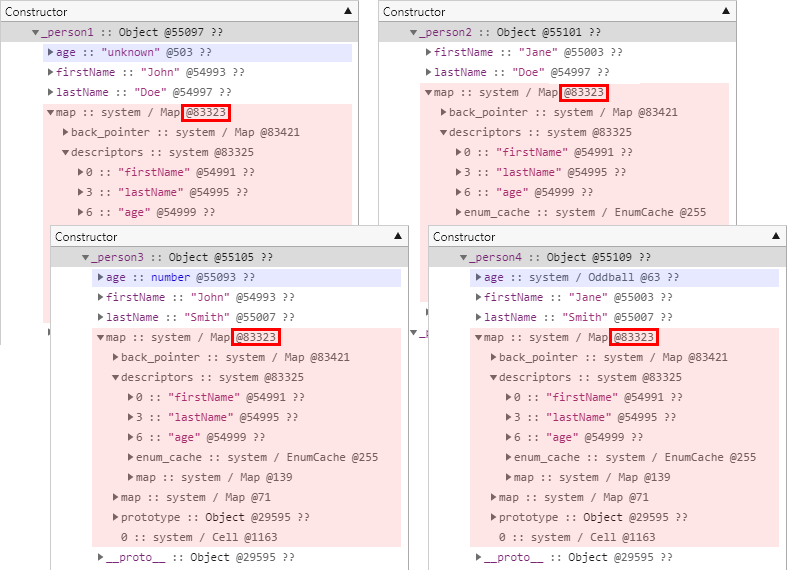
그리고 이번 테스트 결과에서 한 가지 더 주목해서 살펴봐야 할 부분은 age 속성에 정수형 값을 지정한 _person2 개체의 메모리 힙 스냅샷 구조입니다.
본문의 후반부에서 다시 자세히 살펴보겠지만 속성들에 관한 메타 정보가 저장되는 descriptors 필드를 살펴보면 분명히 age 속성에 관한 정보가 동일하게 존재하는데, 다른 개체들과는 달리 _person2 개체의 메모리 힙 스냅샷 구조에는 age 속성이 존재하지 않습니다.
그 이유에 관해서는 잠시 후 다시 자세하게 살펴보도록 하겠습니다.
다른 형식의 요소를 가진 배열 간의 비교
계속해서 이번에는 배열의 히든 클래스에 관해서 살펴보도록 하겠습니다. 배열이 담고 있는 요소의 형식이 히든 클래스에 영향을 미치는지도 확인해볼 필요가 있습니다. 다음은 테스트에 사용한 예제 코드입니다.
// 다른 형식의 요소를 가진 배열 간의 비교
var _inferiorPlanets = ["Mercury", "Venus", "Earth", "Mars"];
var _superiorPlanets = ["Jupiter", "Saturn", "Uranus", "Neptune"];
var _mathConstant = [3.14, 2.71, 1.61, 0.57];
그리고 다음은 테스트 결과입니다.
동일하게 문자열 형식의 요소들을 담고 있는 _inferiorPlanets 배열과 _superiorPlanets 배열은 같은 히든 클래스를 참조하고 있습니다.
반면 Double 형식의 요소들을 담고 있는 _mathConstant 배열은 다른 히든 클래스를 참조합니다.
즉 배열에 담긴 요소들의 형식이 참조하는 히든 클래스에도 영향을 준다는 사실을 확인할 수 있습니다.
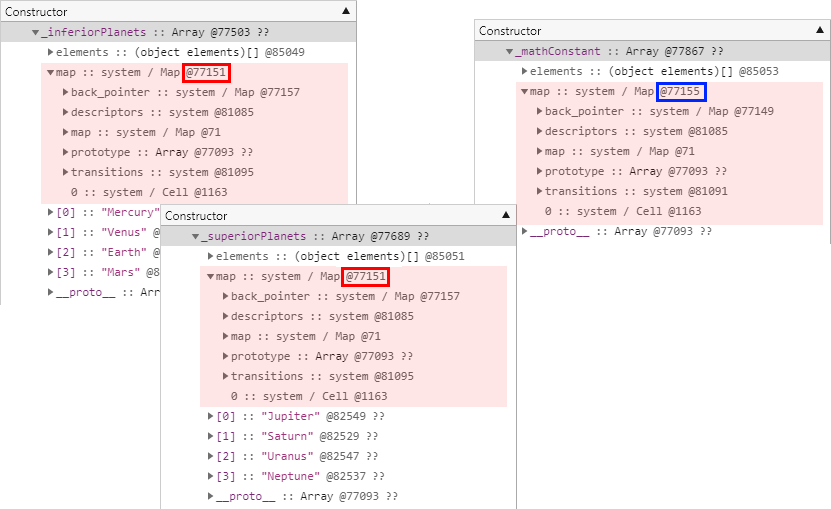
또한 직전 테스트와 마찬가지로 Double 형식의 요소들을 담고 있는 _mathConstant 배열의 메모리 힙 스냅샷 구조가 다른 두 배열과는 상이하게 차이나는 것을 확인할 수 있습니다.
그 이유에 관해서도 잠시 후 다시 자세하게 살펴보도록 하겠습니다.
배열에 같은/다른 형식의 요소 추가 시 히든 클래스 변경 여부
일반적인 속성(잠시 후 자세히 살펴보겠지만 명명된 속성이라고도 합니다)을 가진 개체에 새로운 속성을 추가하면 개체가 참조하는 히든 클래스가 전환된다는 사실은 이미 알고 있습니다. 그렇다면 배열에 요소를 추가하는 경우에도 히든 클래스가 전환될까요? 다음은 이 궁금증을 테스트해 보기 위한 코드입니다.
// 배열에 같은/다른 형식의 요소 추가 시 히든 클래스 변경 여부 1.
var _superiorPlanets = ["Jupiter", "Saturn", "Uranus", "Neptune"];
// --> 첫 번째 스냅샷을 찍습니다.
// 같은 형식의 요소를 추가합니다.
_superiorPlanets.push("Pluto");
// --> 두 번째 스냅샷을 찍습니다.
// 다른 형식의 요소를 추가합니다.
_superiorPlanets.push(3.14);
// --> 세 번째 스냅샷을 찍습니다.다음은 테스트 결과입니다. 추가된 요소의 형식과 관계 없이 동일한 히든 클래스를 참조하고 있습니다. 자 그렇다면 배열에 추가되는 요소의 형식은 히든 클래스에 아무런 영향을 미치지 않는 것으로 이대로 결론을 내리면 되는 것일까요? 사실은 그렇지 않습니다.
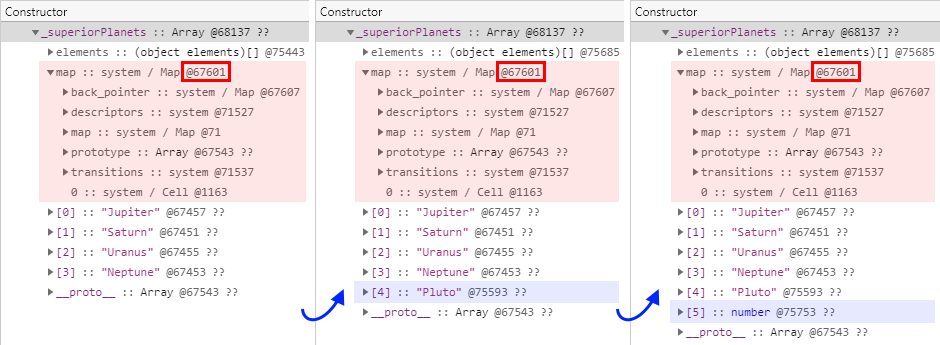
다음과 같은 두 번째 코드를 테스트해 보도록 하겠습니다. 첫 번째 테스트 코드와 거의 동일한 구조를 갖고 있지만 작업 대상 배열의 최초 요소 형식이 다릅니다.
// 배열에 같은/다른 형식의 요소 추가 시 히든 클래스 변경 여부 2.
var _mathConstant = [3.14, 2.71, 1.61, 0.57];
// --> 첫 번째 스냅샷을 찍습니다.
// 같은 형식의 요소를 추가합니다.
_mathConstant.push(0.91);
// --> 두 번째 스냅샷을 찍습니다.
// 다른 형식의 요소를 추가합니다.
_mathConstant.push("Earth");
// --> 세 번째 스냅샷을 찍습니다.다음은 두 번째 테스트의 결과인데, 첫 번째 결과와는 상당히 다른 모습을 보여줍니다. 무엇보다도 다른 형식의 요소를 추가한 뒤의 세 번째 메모리 힙 스냅샷에서는 참조하는 히든 클래스가 변경되었습니다. 게다가 갑자기 메모리 힙 스냅샷의 구조가 확 바뀌어버립니다.
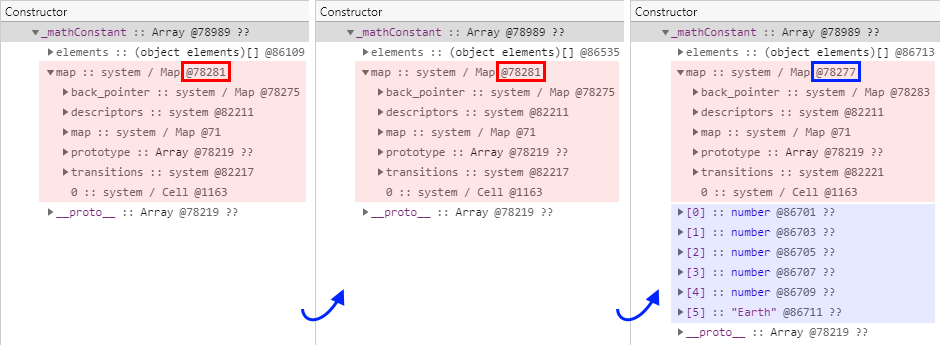
이미 눈치채신 분도 계시겠지만 이번 테스트 결과와 같이 메모리 힙 스냅샷의 구조에 뭔가 특이한 변화가 발생하거나 애초에 예외적인 구조를 갖고 있는 경우에는 대부분 Number 형식이 관여되어 있습니다.
그 이유는 몇 가지 상황에서 V8 엔진이 Number 형식을 특별하게 취급하기 때문입니다.
이 점에 관해서는 잠시 후 다시 자세하게 살펴보도록 하겠습니다.
일반 개체와 JSON.parse() 및 eval() 함수로 생성된 개체 간의 비교
마지막으로 다소 극단적인 방식으로 생성한 개체들 간의 히든 클래스 참조를 비교해보고 이번 섹션을 마무리하도록 하겠습니다.
일반적인 개체 리터럴 방식으로 생성한 개체, JSON.parse() 메서드로 생성한 개체, eval() 함수로 생성한 개체의 히든 클래스를 비교해 보겠습니다.
참고로 개체 리터럴 방식보다 JSON.parse() 메서드 방식으로 개체를 생성하는 것이 더 빠르다고 합니다.
이에 관해서는 다음 링크의 문서에서 잘 설명해주고 있습니다.
다음은 테스트에 사용한 예제 코드입니다.
// 일반 개체와 JSON.parse() 및 eval() 함수로 생성된 개체 간의 비교
var _person1 = { firstName: "John", lastName: "Doe" };
var _person2 = JSON.parse('{ "firstName": "Jane", "lastName": "Doe" }');
var _person3 = eval('({ firstName: "John", lastName: "Smith"})');그리고 다음은 테스트 결과입니다. 개체를 생성한 방법과는 무관하게 세 개체 모두 동일한 히든 클래스를 참조하는 것을 확인할 수 있습니다.
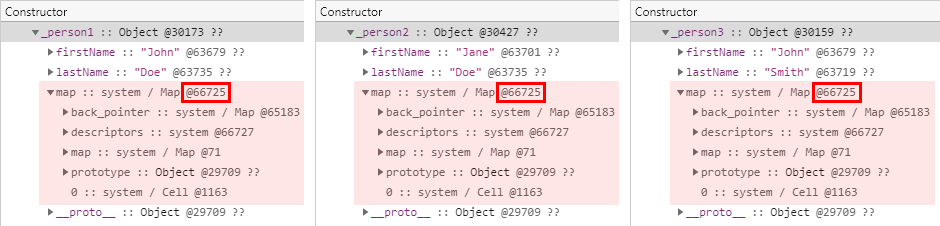
히든 클래스 비교 결과 정리
지금까지의 테스트 결과를 정리해봤을 때 개체 간에 동일한 히든 클래스를 유지하기 위해서는 다음과 같은 조건들을 만족해야 함을 알 수 있습니다. 가장 중요한 사항은 개체가 갖고 있는 속성들의 오프셋이 동일하게 유지되어야 한다는 점입니다. 속성의 오프셋이 변경되거나 값이 저장되는 V8 엔진 내부의 메모리 위치가 바뀌면 히든 클래스도 변경됩니다.
- 개체의 생성자가 같아야 합니다.
- 개체의 속성 이름이 동일하고 속성이 정의되거나 추가되는 순서 및 방식이 같아야 합니다. 다만 속성 값의 형식은 히든 클래스에 영향을 주지 않습니다.
- 배열의 경우 요소들의 형식이 같아야 합니다. 담겨 있거나 추가되는 요소의 형식에 따라서 히든 클래스가 변경될 수도 있고, 변경되지 않을 수도 있습니다.
이번 섹션의 전체 테스트 코드는 hidden_class_compare.js 파일을 다운로드 받아서 확인하실 수 있습니다.
V8 엔진이 숫자를 관리하는 방법
대부분의 프로그래밍 언어는 여러 유형의 형식을 사용하여 다양한 범위의 숫자를 표현합니다.
그래서 새로운 프로그래밍 언어를 접할 때마다 미묘하게 다른 형식 시스템에 대해 매번 새롭게 학습하고는 합니다.
반면 JavaScript에서는 모든 숫자를 Number 형식으로 표현합니다.
언어 사양에 따르면 Number 형식은 IEEE 754 64비트 배정도 부동소수점 형식으로, 간단히 말해서 C/C++ 등의 double 형식과 같다고 생각하시면 됩니다.
따라서 비교적 최근에 새롭게 등장한 BigInt 형식을 논외로 한다면 원론적으로 JavaScript에는 정수라는 개념 자체가 없는 셈입니다.
하지만 코드를 작성하면서 정수를 사용하지 않는 것은 사실상 불가능에 가깝기 때문에 모든 JavaScript 엔진은 정수를 표현하는 나름의 방법을 갖고 있습니다.
그리고 SMI(Small Integer)가 바로 V8 엔진이 정수를 표현하는 방법입니다.
SMI(Small Integer)와 힙 개체
기본적으로 V8 엔진에서 모든 JavaScript 값은 그것이 개체이거나, 배열이거나, 숫자이거나, 문자열이거나 상관없이 모두 개체로 표현되어 힙에 할당됩니다. 그 결과 모든 값을 개체를 가리키는 포인터로 나타낼 수 있게 됩니다. 그러나 정수의 경우에는 사용 빈도가 너무 높기 때문에 동일한 방식으로 관리가 이루어진다면 값이 변경되거나 계산이 수행될 때마다 매번 새로운 개체를 할당해야 하는데 이는 너무 큰 부담입니다. 가령 루프문에서 매번 인덱스 값이 증감될 때마다 할당이 반복된다고 가정해보면 이게 어떤 상황인지 이해하기가 쉬울 것입니다.
그래서 V8 엔진은 포인터 태깅이라는 잘 알려진 기법을 활용하여 특정 범위의 정수 값을 다른 개체와는 다르게 특별 취급합니다. 그리고 이에 해당하는 정수 값을 V8 엔진에서는 SMI(Small Integer)라고 별도로 구분하여 지칭합니다. 가령 일반적인 32비트 포인터는 다음과 같은 구조를 갖습니다.

그러나 V8 엔진은 다음과 같이 포인터의 LSB와 두 번째 LSB에 태깅 값을 지정하여 SMI와 힙 개체 포인터를 구분합니다.
SMI의 태깅 값은 0이고 힙 개체 포인터의 태깅 값은 1, 약한 힙 개체 포인터의 태깅 값은 3입니다.
여기서 SMI에는 포인터 대신 정수값이 직접 저장된다는 점에 주의하시기 바랍니다.
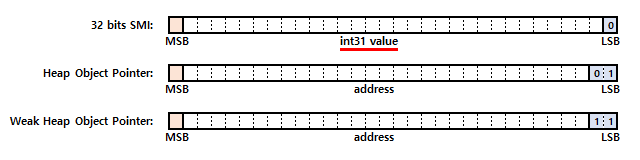
또한 64비트 플랫폼에서 SMI는 다음과 같은 구조를 갖습니다.
여기서 LSB 좌측의 31비트 0값은 단지 패딩일 뿐입니다.
이런 방식을 사용하면 별도의 저장소에서 메타 정보를 따로 관리하지 않고도 SMI와 힙 개체를 손쉽게 구분할 수 있습니다.

정리해보면 32비트 플랫폼에서 SMI에는 포인터가 아닌 -230~230-1 범위의 정수값, 즉 31비트 부호있는 정수값이 직접 저장됩니다. 마찬가지로 64비트 플랫폼에서 SMI에는 -231~231-1 범위의 정수값, 즉 32비트 부호있는 정수값이 직접 저장됩니다. 이처럼 SMI는 힙 메모리에 할당되지 않는 즉치 값(Immediate Values)입니다. 따라서 메모리 힙 스냅샷에는 SMI가 나타나지 않는데, 메모리 힙 스냅샷은 그 이름처럼 힙 메모리에 존재하는 개체들의 현재 상태를 스냅샷으로 표현한 결과이기 때문입니다.
그러나 당연한 얘기지만 모든 숫자가 SMI인 것은 아닙니다.
범위를 넘어서는 정수값 또는 Double 형식의 값을 저장하거나 일부 속성 설정 등에서 값을 박싱해야 하는 경우에는 여전히 힙에 개체로 저장되며 이를 힙 숫자라고 합니다.
그밖에 V8 엔진의 SMI 및 힙 숫자 관련 소스는 다음 링크들을 참고하시기 바랍니다.
그리고 SMI 및 힙 개체에 대한 태깅 값 정의는 다음 소스에서 확인하실 수 있습니다.
kHeapObjectTag 상수, kWeakHeapObjectTag 상수, kSmiTag 상수의 정의를 찾아보시면 됩니다.
숫자 값과 메모리 힙 스냅샷
다음은 SMI를 비롯한 다양한 형식의 값들이 메모리 힙 스냅샷에서 어떤 방식으로 표현되는지 직접 살펴보기 위한 테스트 코드입니다. 각 속성에 가장 빈번하게 사용되는 형식의 값들을 설정했습니다.
// 다양한 형식의 속성을 가진 개체
var _object = {
propInteger: 1,
propDouble: 1.1,
propString: "value string",
propBoolean: true,
propObject: {
prop: "inner object value string"
},
propFunc: function() {
console.log("propFunc");
},
propArray: [0, 1, 2, 3]
};
다음은 이 개체를 메모리 힙 스냅샷으로 살펴본 모습입니다.
개체의 속성들에 관한 메타 정보가 저장되는 descriptors 필드를 살펴보면 일곱 개의 속성 정보가 모두 정상적으로 존재함을 확인할 수 있습니다.
그런데 정작 개체에는 propInteger 속성이 존재하지 않습니다.
그 이유는 방금 전에 설명한 것처럼 즉치 값인 SMI 값 1은 힙 메모리에 할당되지 않기 때문입니다.

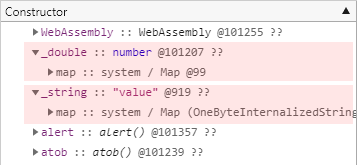
조금 더 극단적인 비교를 위해 이번에는 다음과 같은 전역 변수들을 정의해보도록 하겠습니다. 이 테스트 코드의 개체를 비롯해서 지금까지 살펴본 본문의 모든 개체들은 전역 변수입니다. 따라서 이 변수들은 전역 Window 개체 하위에 존재해야 합니다.
// 간단한 전역 변수들
var _integer = 1;
var _double = 1.1;
var _string = "value";그러나 역시 이 경우에도 SMI 값은 메모리 힙 스냅샷에 나타나지 않습니다. 본문의 앞부분에서 살펴봤던 몇몇 테스트에서 정수형 값이 메모리 힙 스냅샷에 나타나지 않았던 것이 바로 같은 이유 때문입니다.
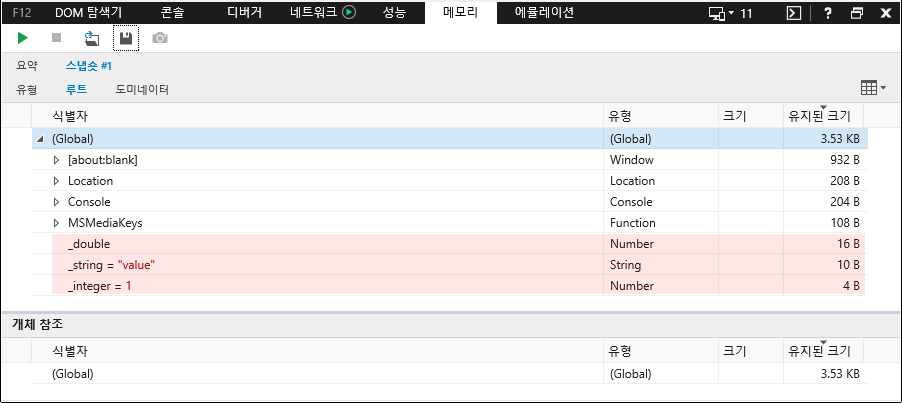
동일한 테스트를 IE11에서 수행해본 결과는 다음과 같습니다. IE11에는 SMI에 대응하는 개념이 없는 것인지, 아니면 있더라도 그것까지 감안하여 메모리 힙 스냅샷을 보여주는 것인지는 확인할 수 없었지만 Chromium Edge와는 달리 모든 변수를 보여주는 것을 확인할 수 있습니다.
V8 엔진이 속성을 관리하는 방법
개인적으로 느낀 V8 엔진의 개체 관리 방식에 대한 인상은 상당히 집요하다는 것입니다. 가령 어떤 식으로든 한 번 더 최적화를 수행할 수 있는 여지가 있다거나 보다 효율적인 방식이 존재한다고 생각되면, 해당 요건을 만족하는 조건이나 상황을 별도의 범주로 분류하여 개별적으로 처리합니다. 그러다 보니 하나의 사항을 관리하는 방식이 이런 경우에는 이렇게, 저런 경우에는 저렇게 각각 따로따로 나누어져 있어서 전체적인 모습을 보기도 쉽지 않고 각각의 사례를 파악하기도 힘듭니다. 이와 같은 관점에서 V8 엔진이 개체를 관리하는 방법을 조금 더 세부적으로 살펴보도록 하겠습니다.
그리고 이번 섹션의 내용 중 상당 부분은 다음 문서를 메모리 힙 스냅샷의 관점에서 다시 재해석한 것이므로 참고하시기 바랍니다.
명명된 속성 vs. 정수 인덱스 속성
기본적으로 V8 엔진은 모든 속성을 명명된 속성(Named Properties)과 정수 인덱스 속성(Integer-Indexed Properties)의 두 가지 범주로 구분하여 관리합니다. 가령 다음 테스트 코드는 명명된 속성으로만 구성된 개체를 생성합니다.
// 명명된 속성 개체
var _person = {
firstName: "John",
lastName: "Doe"
};반면 다음 테스트 코드는 정수 인덱스 속성으로만 구성된 개체를 생성합니다. 정수 인덱스 속성을 일반적으로 요소 또는 배열 인덱스 속성이라고도 하는데, 가장 대표적인 형태인 배열 외에도 그 명칭처럼 단지 속성 이름이 정수인 경우도 이 범주에 포함됩니다.
// 정수 인덱스 속성 개체
var _inferiorPlanets = ["Mercury", "Venus", "Earth", "Mars"];
// 배열 인덱스 속성 개체
var _superiorPlanets = {
0: "Jupiter",
1: "Saturn",
2: "Uranus",
3: "Neptune"
};
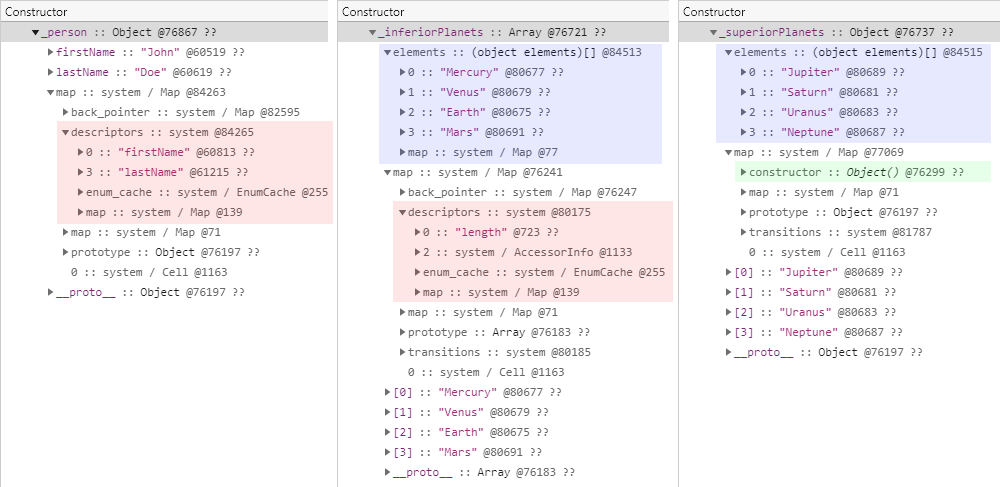
이 테스트 코드의 개체들을 메모리 힙 스냅샷으로 살펴본 모습은 다음과 같습니다.
직접 확인할 수 있는 것처럼 두 범주 간의 가장 큰 차이점은 elements 필드의 유무입니다.
동일한 범주로 분류되는 _inferiorPlanets 개체와 _superiorPlanets 개체 간에도 차이점은 존재합니다.
_inferiorPlanets 개체는 순수한 배열 그 자체이기 때문에 descriptors 필드를 살펴보면 배열 고유의 특징 중 하나인 자동으로 생성된 length 속성이 존재하는 것을 확인할 수 있습니다.
반면 _superiorPlanets 개체는 비록 정수 인덱스 속성의 개체이기는 하지만 본질은 어디까지나 평범한 개체입니다.
따라서 히든 클래스를 살펴보면 length 속성도 존재하지 않고 constructor 필드를 확인해보면 당연히 생성자는 Object() 임을 확인할 수 있습니다.
그러나 정말 중요한 핵심 사항은 V8 엔진이 명명된 속성과 정수 인덱스 속성을 내부적으로 각각 별도의 데이터 구조에 저장하여 서로 다른 방식으로 관리한다는 사실입니다. 그 이유는 두 범주의 속성이 사용되는 패턴이 서로 다르기 때문에 보다 효율적으로 속성을 추가하고 접근하기 위함입니다. 다음 다이어그램은 V8 엔진이 관리하는 메모리 상에서 기본적인 JavaScript 개체가 어떤 구조를 갖는지 보여줍니다.
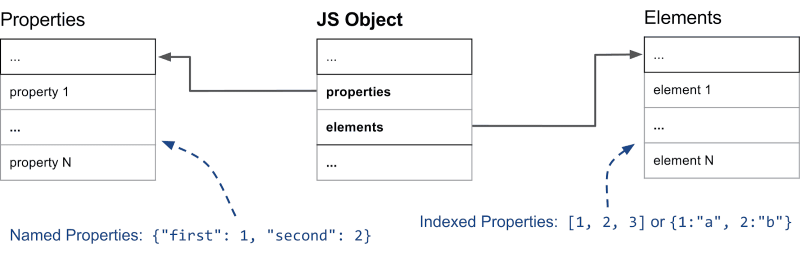 original image source: https://v8.dev/blog/fast-properties
original image source: https://v8.dev/blog/fast-properties
가령 정수 인덱스 속성은 단일 요소보다는 주로 연속된 범위를 대상으로 접근하는 패턴 위주로 사용되며, 이런 점을 감안하여 대부분의 경우 내부적으로 간단한 배열로 관리됩니다.
그러나 언제나 그런 것만은 아닌데 드물게 메모리를 절약하기 위한 목적으로 사전 형태로 관리되는 경우도 있습니다.
정수 인덱스 속성의 내부 구조는 이번 테스트 결과에서도 확인할 수 있는 것처럼 대부분 메모리 힙 스냅샷의 elements 필드를 통해서 엿볼 수 있지만, 역시 여기에도 예외는 존재합니다.
보다 자세한 내용은 정수 인덱스 속성을 집중적으로 살펴보면서 다시 알아보도록 하겠습니다.
명명된 속성 역시 비슷한 방식으로 별도의 배열에 저장되며 조건에 따라 사전 형태로 관리되는 경우도 역시 존재합니다.
정수 인덱스 속성과는 다르게 키만 가지고서는 배열 내부의 위치를 손쉽게 알아낼 수가 없기 때문에 별도의 메타 정보가 필요한데, 지금까지 본문의 시리즈에서 수 차례 살펴본 히든 클래스가 바로 그 메타 정보입니다.
히든 클래스에는 속성의 개수 및 이름 같은 개체의 형태, 프로토타입에 대한 참조, 속성 이름에 대한 인덱스 매핑 정보 등이 저장되며, 메모리 힙 스냅샷의 map 필드를 통해서 그 구조를 엿볼 수 있습니다.
다음 다이어그램은 히든 클래스의 대략적인 구조를 보여줍니다.
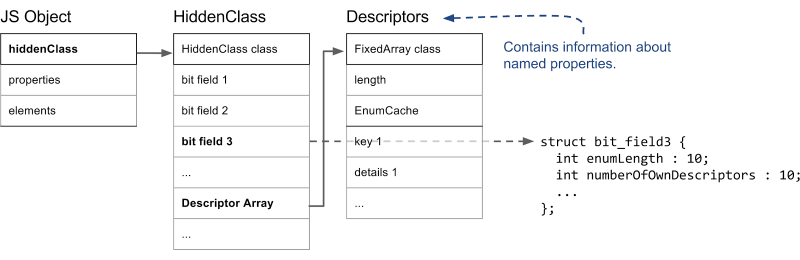 original image source: https://v8.dev/blog/fast-properties
original image source: https://v8.dev/blog/fast-properties
이 다이어그램과 본문에서 살펴봤던 일반적인 개체에 대한 메모리 힙 스냅샷을 서로 간단히 비교하여 살펴보겠습니다.
방금 언급했던 것처럼 메모리 힙 스냅샷으로 표현된 모든 개체에서 히든 클래스는 map 필드로 표현됩니다.
다만 속성과 관련된 다양한 개수를 저장하고 있는 히든 클래스의 세 번째 필드처럼 메모리 힙 스냅샷에는 표현되지 않는 정보가 더 많습니다.
히든 클래스 하위의 서술자 배열(Descriptor Array)에는 명명된 속성의 이름과 실제 값이 저장되어 있는 위치를 비롯한 다양한 정보가 저장되며 이는 메모리 힙 스냅샷에서는 map 필드 하위의 descriptors 필드로 표현됩니다.
그리고 다시 그 하위에 위치한 enum_cache 필드는 속성의 특성 중 enumerable 값이 true인 명명된 키에 대한 정보만 저장되는 EnumCache를 나타냅니다.
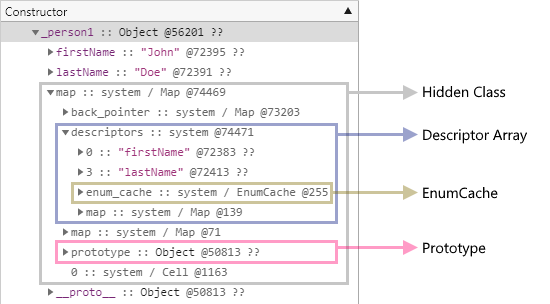
EnumCache는 사실상 for-in 구문을 효과적으로 지원하기 위한 기능이며 다음 링크의 문서에 관련 사항이 잘 설명되어 있습니다.
그리고 서술자 배열 관련 소스는 다음 링크를 참고하시기 바랍니다.
마지막으로 히든 클래스 관련 소스는 다음 링크를 참고하시기 바랍니다. 무엇보다 이 소스의 주석에는 히든 클래스의 구조가 상세하게 잘 기술되어 있습니다.
메모리 힙 스냅샷을 이용해서 명명된 속성 및 정수 인덱스 속성의 정보를 살펴볼 때 기억해야 할 점은 V8 엔진 내부의 정보를 그대로 완벽하게 제공하는 것은 아니라는 점을 이해하는 것입니다. 개체를 관리하는 주체는 V8 엔진이고 한번 걸러진 메모리 힙 스냅샷을 구성하여 표현하는 주체는 어디까지나 Chromium Edge 등의 브라우저라는 점을 기억해두시기 바랍니다.
명명된 속성 세부 사항
보통 V8 엔진을 염두에 두지 않고, 코드를 작성하기 위해서 명명된 속성을 사용할 때는 마치 단순한 사전 형태의 구조를 갖고 있는 것처럼 보입니다. 이는 언어 사양으로부터 비롯된 특징이기도 합니다. 그러나 V8 엔진은 내부적으로 가급적 사전 형태의 구조를 피하기 위해서 다양한 방식으로 명명된 속성을 관리하는데, 그 이유는 사전 형태의 구조가 결국 인라인 캐싱 같은 핵심적인 최적화 기법을 방해하는 요소로 작용하기 때문입니다.
명명된 속성은 내부적으로 다음과 같은 세 가지 범주로 다시 분류되어 관리됩니다.
- 개체 내 속성(In-Object Properties)
- 일반적인/빠른 속성(Normal/Fast Properties)
- 느린/사전 속성(Slow/Dictionary Properties)
먼저 개체 내 속성은 V8 엔진에서 사용할 수 있는 가장 빠른 속성으로 그 이름처럼 개체 내부에 저장되어 아무런 우회 없이 직접 접근할 수 있는 속성입니다. 개체에 저장할 수 있는 개체 내 속성의 개수는 개체의 초기 크기에 따라서 미리 결정됩니다.
만약 개체가 생성된 이후, 내부 공간이 허용하는 양보다 더 많은 속성이 추가되면 간단한 배열 형태의 속성 저장소(Properties Store)로 이동하게 됩니다. 이렇게 되면 비록 접근 경로는 한 단계 더 추가되지만 개체와 독립적으로 속성을 확장할 수 있다는 장점이 생깁니다. 이런 선형적인 형태의 속성 저장소에 저장된 속성을 빠른 속성이라고 부릅니다. 가령 개체 생성 이후에 속성이 추가되기만 하고 삭제되지는 않았다면 대부분 빠른 속성 상태일 것입니다. 빠른 속성은 앞에서 언급했던 것처럼 히든 클래스의 서술자 배열을 활용하여 속성 이름으로 속성 저장소 상의 실제 위치를 찾는 방식으로 간단하게 접근이 가능합니다. 물론 인라인 캐싱 같은 다양한 최적화 기법의 이점을 얻을 수도 있습니다. 다음 다이어그램은 개체 내 속성과 빠른 속성을 보여줍니다.
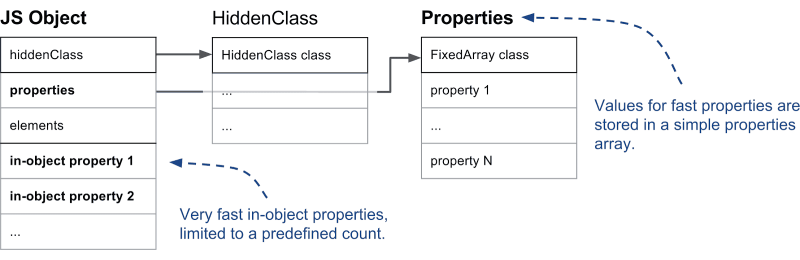 original image source: https://v8.dev/blog/fast-properties
original image source: https://v8.dev/blog/fast-properties
다음과 같은 테스트 코드를 사용하여 개체 내 속성 상태의 개체를 생성하고 메모리 힙 스냅샷으로 살펴보겠습니다.
// 명명된 속성 세부 사항
var _namedProp = {
propA: "A",
propB: "B"
};지금까지 계속해서 봐왔던 일상적인 결과입니다.
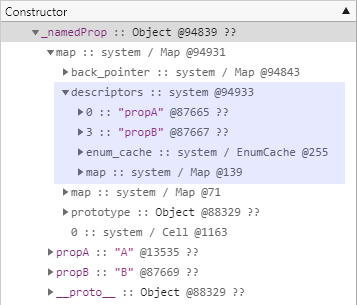
이 상태에서 다음과 같은 코드를 추가적으로 수행하여 몇 가지 속성을 추가해봅니다. 이 코드로 인해서 개체는 빠른 속성 상태로 변경됩니다.
...
_namedProp.propC = "C";
_namedProp.propD = "D";
다시 메모리 힙 스냅샷을 찍어보면 다음과 같이 배열 형태의 속성 저장소를 표현하는 properties 필드가 새로 추가되었음을 확인할 수 있습니다.
개체 생성 이후에 추가한 속성들은 이 properties 필드에 관련 정보가 표현됩니다.
만약 테스트 코드를 직접 입력하면서 따라해보고 있다면 아직 브라우저를 닫지 마시기 바랍니다.
한 가지 단계가 더 남아 있습니다.

반면 개체가 생성된 이후에 지속적으로 많은 속성을 추가 및 삭제하게 되면 히든 클래스와 서술자 배열을 관리하는 데 오히려 더 많은 부하가 발생하게 됩니다. 이에 대응하는 속성이 소위 말하는 느린 속성입니다. 느린 속성의 개체는 속성을 저장하기 위한 사전 형태의 자체적인 속성 저장소를 갖습니다. 이 상태에서는 속성과 관련된 메타 정보를 더 이상 히든 클래스와 서술자 배열에 저장하지 않으며 속성 사전에서 자제적으로 관리합니다. 결과적으로 더 이상 히든 클래스를 신경쓰지 않고 속성을 추가하거나 삭제할 수는 있지만 인라인 캐싱 등이 참고할 수 있는 히든 클래스가 존재하지 않으므로 상대적으로 처리 속도가 대부분의 경우 더 느려집니다. 다음 다이어그램은 느린 속성을 보여줍니다.
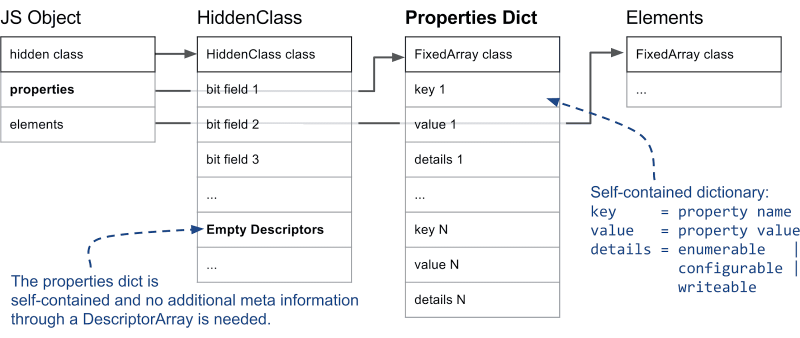 original image source: https://v8.dev/blog/fast-properties
original image source: https://v8.dev/blog/fast-properties
마지막으로 이번에는 다음과 같은 코드를 추가적으로 수행하여 테스트 개체에 몇 가지 속성을 추가하고 삭제해봅니다. 이 코드로 인해서 개체는 느린 속성 상태로 변경됩니다.
...
_namedProp.propE = "E";
_namedProp.propF = "F";
delete _namedProp.propD;
_namedProp.propG = "G";
_namedProp.propH = "H";
delete _namedProp.propG;
_namedProp.propI = "I";
_namedProp.propJ = "J";
delete _namedProp.propI;
다시 메모리 힙 스냅샷을 찍어보면 개체의 구조가 상당히 변경되었음을 확인할 수 있습니다.
일단 히든 클래스 하위의 descriptors 필드와 enum_cache 필드가 아예 사라졌습니다.
properties 필드의 경우에도 직전의 결과와 이름은 동일하지만 형식이 변경되었으며 개체에 존재하는 모든 속성 정보가 properties 필드로 이동한 것을 확인할 수 있습니다.
또한 저장되는 정보의 내용 자체도 다릅니다.
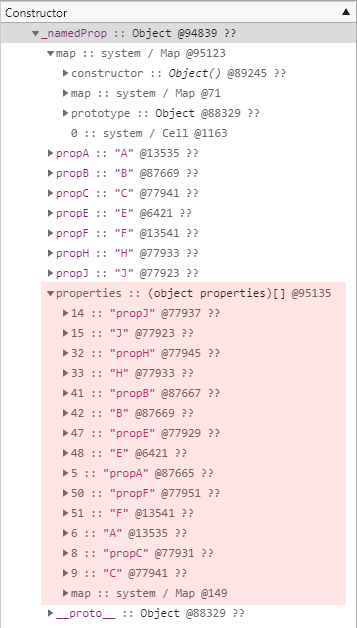
지금까지 살펴본 명명된 속성에 대한 다양한 정보를 바탕으로 얻을 수 있는 결론은 명확합니다. 가급적 개체를 생성함과 동시에 필요한 모든 속성을 함께 생성해야 합니다. 그리고 불가피한 경우가 아니라면 이미 존재하는 속성을 삭제하지 마십시오. 대신 삭제되었음을 뜻하는 구분자 값을 설정하는 등의 널리 사용되는 다른 기법을 활용할 수 있을 것입니다.
정수 인덱스 속성 세부 사항
정수 인덱스 속성은 명명된 속성과는 달리 항상 별도의 요소 저장소(Elements Store)에 저장되며 이미 살펴본 것처럼 이 저장소는 메모리 힙 스냅샷에서 elements 필드로 표현됩니다.
여기까지만 들어보면 명명된 속성보다 훨씬 간단할 것 같지만, 정작 문제는 V8 엔진이 내부적으로 구분하는 요소의 종류가 거의 20여 가지 유형에 달한다는 점입니다.
다음 소스에서 ElementsKind 열거형의 값 목록을 확인해보면 이를 확인할 수 있습니다.
가령 요소가 SMI인지(PACKED_SMI_ELEMENTS, HOLEY_SMI_ELEMENTS), 태깅되지 않은 double 값인지(PACKED_DOUBLE_ELEMENTS, HOLEY_DOUBLE_ELEMENTS), 태깅된 힙 개체인지(PACKED_ELEMENTS, HOLEY_ELEMENTS) 등등의 기준에 따라서 다양한 유형으로 구분되어 처리됩니다.
그러나 가장 중요한 구분 기준은 각 열거형의 이름에서 알 수 있듯이 요소가 채워져 있는지(PACKED_...), 아니면 구멍이 나 있는지(HOLEY_...) 여부입니다.
다음과 같은 테스트 코드를 수행하여 채워진 요소 개체와 구멍난 요소 개체를 생성해 보겠습니다.
// 채워진 요소 개체
var _elementsPacked = ["A", "B", "C"];
// 구멍난 요소 개체
var _elementsHoley = ["A", "B", "C"];
delete _elementsHoley[1];
_elementsHoley.__proto__ = {1: "P"};두 개체의 메모리 힙 스냅샷 결과를 비교해보면 다음과 같습니다. 대충만 살펴봐도 루프문 등을 수행한다고 가정할 때 어느 쪽의 속도가 더 빠른지는 굳이 설명할 필요가 없을 것입니다.
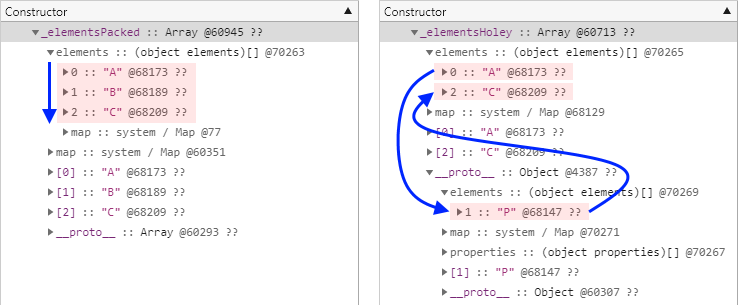
다음 다이어그램은 비슷한 상황을 다른 관점에서 보여줍니다. 배열의 요소에 구멍이 존재할 경우, 요소를 찾기 위해서는 프로토타입 체인을 반복해서 찾아봐야 합니다. 반면 모든 요소가 채워진 배열에서는 프로토타입 체인까지 찾아보지 않고도 개체 자체만으로 조회를 마칠 수 있습니다.
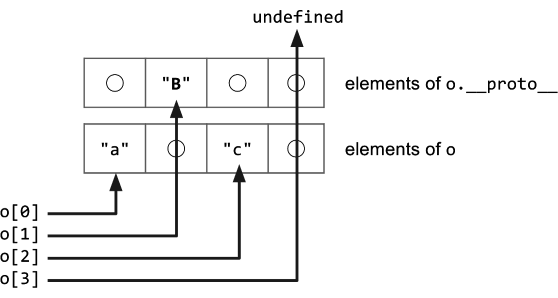 original image source: https://v8.dev/blog/fast-properties
original image source: https://v8.dev/blog/fast-properties
따라서 가급적 배열에서는 특정 요소를 제거한다거나 빼먹고 생성하지 말아야 합니다. 이미 '배열에 같은/다른 형식의 요소 추가 시 히든 클래스 변경 여부' 섹션에서 살펴본 것처럼 배열은 기존 요소들과 같은 형식의 요소를 추가하더라도 명명된 속성과는 달리 히든 클래스가 변경되지 않습니다. 모든 요소의 형식이 동일하다면 C/C++ 등의 언어에서 사용할 때처럼 배열 생성 시에 일정한 크기를 미리 설정하는 대신, 필요할 때마다 인덱스 0부터 순차적으로 요소를 추가하여 사용하는 것도 나쁘지 않습니다.
두 번째로 중요한 정수 인덱스 속성의 구분 기준은 빠른 요소(Fast Elements) vs. 느린/사전 요소(Slow/Dictionary Elements)입니다. 마치 명명된 속성의 빠른 속성 및 느린 속성 간의 차이점과 비슷한 관점에서 이해하시면 됩니다. 빠른 요소는 요소의 인덱스가 요소 저장소의 인덱스에 매핑되는 간단한 내부 배열이며, 지금까지 살펴본 배열은 대부분 이 범주에 속합니다.
그러나 특정 상황에서는 이런 단순한 배열 구조가 오히려 메모리를 낭비하는 것과 같은 결과를 만들어내는 경우가 있습니다. 다음 테스트 코드와 같은 상황이 바로 그런 경우로, 단순히 빠른 요소 방식을 사용할 경우 이 코드는 단 하나의 요소를 위해 요소 일만 개에 해당하는 공간을 메모리에 할당하게 됩니다.
// 느린/사전 요소 개체
var _elementsWasteful = [];
_elementsWasteful[9999] = "Wasteful";대신 V8 엔진은 이런 상황을 유연하게 감지하여 일반적인 배열 구조 대신 사전 형태의 구조를 사용함으로써 속도를 희생하는 대가로 메모리를 절약하는데 이를 느린/사전 요소라고 합니다. 그러나 이런 내부적인 처리는 메모리 힙 스냅샷에서는 잘 드러나지 않습니다. 가령 다음 메모리 힙 스냅샷에서 유일하게 차이를 짐작해 볼 수 있는 부분은 요소의 일련번호가 8이라는 뜬금없는 값이라는 점 뿐입니다. 이런 경우 V8 엔진은 키, 값, 서술자의 삼중항이 저장되는 사전을 생성하는데 이 사전의 구조가 요소 값의 일련번호에 영향을 주는 것입니다.
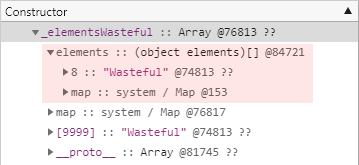
마지막으로 한 가지 범주의 배열만 더 살펴보고 본문을 마무리하도록 하겠습니다.
V8 엔진은 모든 요소가 각각 SMI 또는 double 형식으로만 구성된 배열을 특별하게 다루며, 이미 언급했던 것처럼 각각을 의미하는 열거형이 따로 정의되어 있을 정도입니다(PACKED/HOLEY_SMI_ELEMENTS 및 PACKED/HOLEY_DOUBLE_ELEMENTS).
SMI 요소로만 구성된 배열은 가비지 컬렉터가 검토할 필요조차 없는 아주 특별한 배열입니다.
그리고 배열에서는 double 형식도 거의 SMI에 준하는 특별한 대우를 받는데, 가령 double 형식의 명명된 속성이 힙 숫자로 관리되는 것과는 달리 double 형식으로만 구성된 배열은 원시 double 형식의 내부 배열로 관리됩니다.
다음의 테스트 코드는 각각 요소가 SMI, double, 그리고 문자열로만 구성된 배열을 생성합니다.
// SMI, Double, 문자열 배열 개체
var _elementsInteger = [1, 2, 3];
var _elementsDouble = [1.1, 2.2, 3.3];
var _elementsString = ["A", "B", "C"];
그리고 다음은 이 개체들을 메모리 힙 스냅샷으로 비교한 결과입니다.
명명된 속성에서 SMI 값이 메모리 힙 스냅샷에 나타나지 않았던 것처럼 SMI 또는 double 형식으로만 구성된 배열 역시 메모리 힙 스냅샷에서는 요소가 나타나지 않습니다.
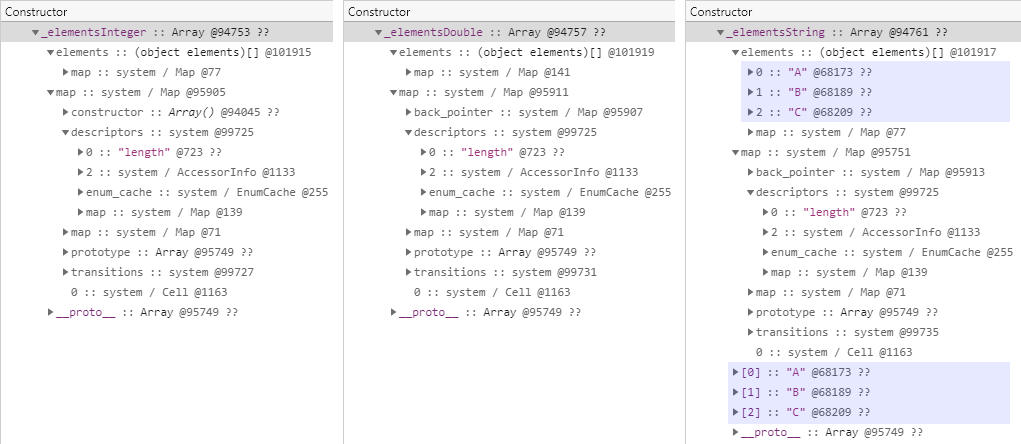
그러나 SMI 또는 double 형식으로만 구성된 배열에 다른 형식의 요소를 추가하게 되면 더이상 내부적으로 원시 형식의 배열을 유지할 수가 없게 됩니다.
그리고 우리는 그 결과를 이미 '배열에 같은/다른 형식의 요소 추가 시 히든 클래스 변경 여부' 섹션에서 직접 살펴본 바 있습니다.
정리
본문에서는 개체의 히든 클래스를 동일하게 유지하기 위해 웹 클라이언트 개발자가 알고 있어야 할 사항들을 메모리 힙 스냅샷의 관점에서 조금 더 구체적인 사례 위주로 살펴본 다음, 한 단계 더 깊숙하게 들어가서 V8 엔진이 내부적으로 JavaScript 개체의 속성을 어떠한 범주로 분류하여 관리하는지 검토해봤습니다.
이어지는 글에서는 V8 엔진의 소스를 다운로드 받고 빌드하여 디버그 쉘인 D8을 활용해서 V8 엔진의 동작 상태를 검토할 수 있는 환경을 만들어보겠습니다.
- IE11을 이용한 JavaScript 디버깅 01, F12 개발자 도구 콘솔 창 2019-01-01 08:00
- IE11을 이용한 JavaScript 디버깅 02, console 개체 2019-01-08 08:00
- IE11을 이용한 JavaScript 디버깅 03, F12 개발자 도구 DOM 탐색기 창 Part 1 2019-01-15 08:00
- IE11을 이용한 JavaScript 디버깅 04, F12 개발자 도구 DOM 탐색기 창 Part 2 2019-01-22 08:00
- IE11을 이용한 JavaScript 디버깅 05, F12 개발자 도구 디버거 창 Part 1 2019-01-29 08:00
- IE11을 이용한 JavaScript 디버깅 06, F12 개발자 도구 디버거 창 Part 2 2019-02-12 08:00
- IE11을 이용한 JavaScript 디버깅 07, F12 개발자 도구 디버거 창 Part 3 2019-02-19 08:00
- IE11을 이용한 JavaScript 디버깅 08, F12 개발자 도구 디버거 창 Part 4 2019-02-26 08:00
- IE11을 이용한 JavaScript 디버깅 09, F12 개발자 도구 디버거 창 Part 5 2019-03-05 08:00
- IE11을 이용한 JavaScript 디버깅 10, F12 개발자 도구 네트워크 창 Part 1 2019-03-19 08:00
- IE11 및 Chromium Edge에서 메모리 힙 스냅샷 찍기 2020-02-25 08:00
- IE11 및 Chromium Edge에서 메모리 힙 스냅샷 비교하기 2020-03-10 08:00
- Chromium Edge의 메모리 힙 스냅샷 분석을 위한 V8 엔진의 이해 1. 2020-03-24 08:00
- Chromium Edge의 메모리 힙 스냅샷 분석을 위한 V8 엔진의 이해 2. 2020-04-07 08:00
- Visual Studio Community로 V8 엔진 다운로드 및 빌드하고 간단히 살펴보기 2020-04-21 08:00
- IE11 및 Chromium Edge에서 가상의 메모리 누수 상황 재현 및 해결하기 2020-05-05 08:00




