
 sign in
sign in
 join
join
Chromium Edge의 메모리 힙 스냅샷 분석을 위한 V8 엔진의 이해 1.
본문의 주제를 처음 준비하던 2018년 후반만 해도 본문은 'IE11을 이용한 JavaScript 디버깅' 시리즈의 일부분으로 구성되어 몇 편에 걸쳐 나뉘어 제공될 예정이었습니다. 그러나 공교롭게도 거의 동일한 시기에 Microsoft가 Chromium Edge에 대한 구체적인 계획을 발표함으로써 시리즈 자체의 필요성이 크게 줄어들었고, 결과적으로 다루고자 계획했던 내용을 끝까지 진행하지 못한 체 시리즈는 사실상 중단된 상태입니다.
비록 'IE11을 이용한 JavaScript 디버깅' 시리즈의 내용이 IE11의 F12 개발자 도구를 활용하는 방법에 중점을 두고 있기는 하지만, 최종 목표는 단순히 그에 그치지 않고 상대적으로 UI 및 기능이 단순한 IE11의 F12 개발자 도구에 친숙해진 다음, 거의 동일한 UI와 기능을 제공하지만 대폭 개선된 Classic Edge를 다루고, 또다시 보다 풍부한 기능을 제공하는 Chrome 등의 최신 브라우저로 접근을 확대해나가는 것이었습니다. 그러나 중간 징검다리 역할을 해줄 Classic Edge의 존재 위치가 불확실해짐에 따라 시리즈의 전반적인 맥락이 끊어졌다는 판단이었습니다.
드디어 2020년 초인 현재, 정식으로 배포되기 시작한 Microsoft의 Chromium Edge는 나름대로 순조롭게 시장에 안착하고 있는 것으로 보입니다. F12 개발자 도구라는 관점에서만 본다면 Chrome과 거의 동일한 UI 및 기능을 제공하고 있어서 기본적인 수준에서는 둘 중 어떤 브라우저를 선택하더라도 별다른 차이가 없을 듯합니다. 개인적으로 과거 IE11/Classic Edge 계열과 Chrome 계열로 나눴던 F12 개발자 도구 그룹을 이제는 IE11 계열과 Chromium Edge/Chrome 계열로 분류해도 무방할 것 같습니다. (FireFox까지 다루고 싶은 욕심도 있었지만 현실적으로 제 역량으로는 무리라고 생각되어 본문에서는 다루지 않습니다.)
본문에서는 IE11과 Chromium Edge의 F12 개발자 도구를 활용한 메모리 힙 스냅샷의 비교/분석을 통해 웹 브라우저의 메모리 누수를 감지하는 가장 기본적인 방법을 살펴봅니다.
시리즈 목차
- IE11 및 Chromium Edge에서 메모리 힙 스냅샷 찍기: 메모리 힙 스냅샷 찍기, 용어 및 기본적인 화면 구성 이해
- IE11 및 Chromium Edge에서 메모리 힙 스냅샷 비교하기: 메모리 힙 스냅샷 간 비교/분석 방법, 분리된 DOM 트리 검토 및 실습
- Chromium Edge의 메모리 힙 스냅샷 분석을 위한 V8 엔진의 이해 1: V8 엔진 실행 파이프라인, 인라이닝, 히든 클래스, 인라인 캐싱, 추적 로그 검토 방법
- Chromium Edge의 메모리 힙 스냅샷 분석을 위한 V8 엔진의 이해 2: 동일한 히든 클래스를 유지하기 위한 다양한 조건, SMI, 명명된 속성, 정수 인덱스 속성
- Visual Studio Community로 V8 엔진 다운로드 및 빌드하고 간단히 살펴보기: V8 엔진 소스 다운로드 및 빌드, depot_tools 설치, 기초적인 D8 옵션 플래그
- IE11 및 Chromium Edge에서 가상의 메모리 누수 상황 재현 및 해결하기: 잘못된 jQuery 사용 패턴, 전역 jQuery 캐시, Performance 창, Allocation instrumentation on timeline 프로파일링
문서 목차
들어가기 전에
지금까지 두 차례에 걸쳐 IE11 및 Chromium Edge에서 하나 이상의 메모리 힙 스냅샷을 찍고 각각 분석하거나 서로 비교하는 가장 기본적인 방법을 살펴봤습니다. 또한 브라우저에서 제공하는 기능과 용어에 대해 알아보고 대표적인 메모리 누수 패턴 중 하나인 분리된 DOM 트리의 간단한 사례를 직접 검토해봤습니다. 어쩌면 기대했던 것보다 쉽지 않은 작업이라고 느끼셨을 수도 있습니다.
특히 Chromium 계열의 메모리 힙 스냅샷은 제공하는 정보가 너무 방대하고 이를 일부라도 이해하기 위해서는 미리 알고 있어야만 하는 선행 정보가 상당히 많아서 이런 점이 초보 개발자에게는 큰 진입 장벽으로 작용합니다. 반면 몇 차례 강조했던 것처럼 IE11의 메모리 힙 스냅샷은 일반적인 웹 개발자가 '기대하는 수준의 정보'를 충분히 '예상할 수 있는 형태'로 보여줍니다. 다만 그렇다고 해서 IE11의 활용성이 더 높다는 뜻은 절대로 아니라는 점을 명확하게 인식하고 있어야만 합니다. 본문의 시리즈에서 IE11을 병행하여 살펴보는 이유는 어디까지나 우리나라의 특수한 현실을 감안하고 초보 개발자에 대한 진입 장벽을 조금이라도 낮추기 위함입니다.
그런 취지에서 이번 글에서는 잠시 IE11은 머릿속 한쪽에 미뤄두고 Chromium 계열의 V8 엔진이 JavaScript 개체를 다루는 방법에 대해서 특히 메모리 힙 스냅샷의 관점에서 조금 더 깊게 살펴보고자 합니다. 이 단계를 거치지 않고서는 Chromium 계열의 메모리 힙 스냅샷을 충실하게 분석하기가 어렵습니다. V8 내부의 구현 세부 사항까지는 모르더라도 V8이 JavaScript 개체를 구조적으로 어떻게 관리하는지는 이해하고 있는 것이 바람직합니다. 이는 본문의 주제인 메모리 누수 감지에 준하는 또 다른 중요한 주제인 응용 프로그램의 수행 속도 향상과도 밀접하게 관련된 문제입니다.
예제 코드 살펴보기
다음은 본문에서 사용할 예제 HTML 파일의 내용입니다. 이번에도 외부 라이브러리는 아무것도 사용하지 않았으며 코드가 다소 복잡하게 보이지만 제공하는 기능은 매우 단순합니다. (새 창에서 보기)
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>메모리 누수 - Chromium Hidden Class - Loop Benchmark</title>
<style>
body {
font-size: 12px;
font-family: Tahoma;
}
input[type="text"] {
display: block;
width: 100px;
height: 24px;
margin: 5px;
text-align: right;
}
input[type="button"] {
display: inline-block;
width: 150px;
height: 30px;
margin: 5px;
}
</style>
</head>
<body>
<input id="txtLoopCount" type="text" value="1000" />
<input type="button" value="Fixed Property" onclick="fnFixedProp();" />
<input type="button" value="Random Property" onclick="fnRandomProp();" />
<script>
/**
* @description 미리 지정된 속성을 가진 개체를 지정한 개수만큼 생성합니다.
*/
function fnFixedProp() {
var loopCount = document.getElementById("txtLoopCount").value;
console.log("Fixed Property: loopCount-%s", loopCount);
var startTimestamp = (new Date()).getTime();
var array = [];
for (var i = 0; i < loopCount; i++) {
var obj = {
// 고정된 10개의 속성을 지정한 상태로 개체를 생성합니다.
prop0: "", prop1: "", prop2: "", prop3: "", prop4: "",
prop5: "", prop6: "", prop7: "", prop8: "", prop9: ""
};
for (var j = 0; j < 10; j++) {
var text = getRandomString(4);
obj["prop" + j] = text;
}
array.push(obj);
}
var endTimestamp = (new Date()).getTime();
console.log(" ==> Execution Time: %s sec.", ((endTimestamp - startTimestamp) / 1000).toFixed(3));
}
/**
* @description 임의의 이름으로 속성을 매번 추가하여 지정한 개수만큼 개체를 생성합니다.
*/
function fnRandomProp() {
var loopCount = document.getElementById("txtLoopCount").value;
console.log("Random Property: loopCount-%s", loopCount);
var startTimestamp = (new Date()).getTime();
var array = [];
for (var i = 0; i < loopCount; i++) {
var obj = {
// 아무런 속성도 지정하지 않은 상태로 개체를 생성합니다.
};
for (var j = 0; j < 10; j++) {
var text = getRandomString(4);
obj["prop" + text] = text;
}
array.push(obj);
}
var endTimestamp = (new Date()).getTime();
console.log(" ==> Execution Time: %s sec.", ((endTimestamp - startTimestamp) / 1000).toFixed(3));
}
/**
* @description 지정한 길이로 임의의 문자열을 반환합니다.
* @param {number} length - 문자열 길이
* @return {string} 결과 문자열
*/
function getRandomString(length) {
var result = "";
var baseSet = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789";
for (var index = 0; index < length; index++) {
result += baseSet.charAt(Math.floor(Math.random() * baseSet.length));
}
return result;
}
</script>
</body>
</html>예제 HTML 파일의 기능부터 잠시 살펴보도록 하겠습니다. Chromium Edge에서 예제 페이지를 실행해보면 다음과 같은 단순한 모습을 보여줍니다.
먼저 Fixed Property 버튼을 클릭하면 fnFixedProp() 함수가 실행되어 미리 속성 이름이 결정된 10개의 속성을 가진 개체를 텍스트 상자에 지정한 개수만큼 생성하고 작업에 걸린 시간을 Console 창에 출력합니다.
반면 Random Property 버튼을 클릭하면 fnRandomProp() 함수가 실행되어 매번 런타임에 속성 이름이 결정되는 10개의 속성을 가진 개체를 텍스트 상자에 지정한 개수만큼 생성하고 작업에 걸린 시간을 Console 창에 출력합니다.
두 함수의 코드 정의에 차이점이 존재하는 부분을 강조하여 하이라이트 해놓았으므로 비교해보시기 바랍니다.
그리고 코드 마지막 부분의 getRandomString() 함수는 임의로 만들어지는 속성 이름과 속성 값으로 사용될 무작위 문자열을 생성하는 유틸리티 함수입니다.
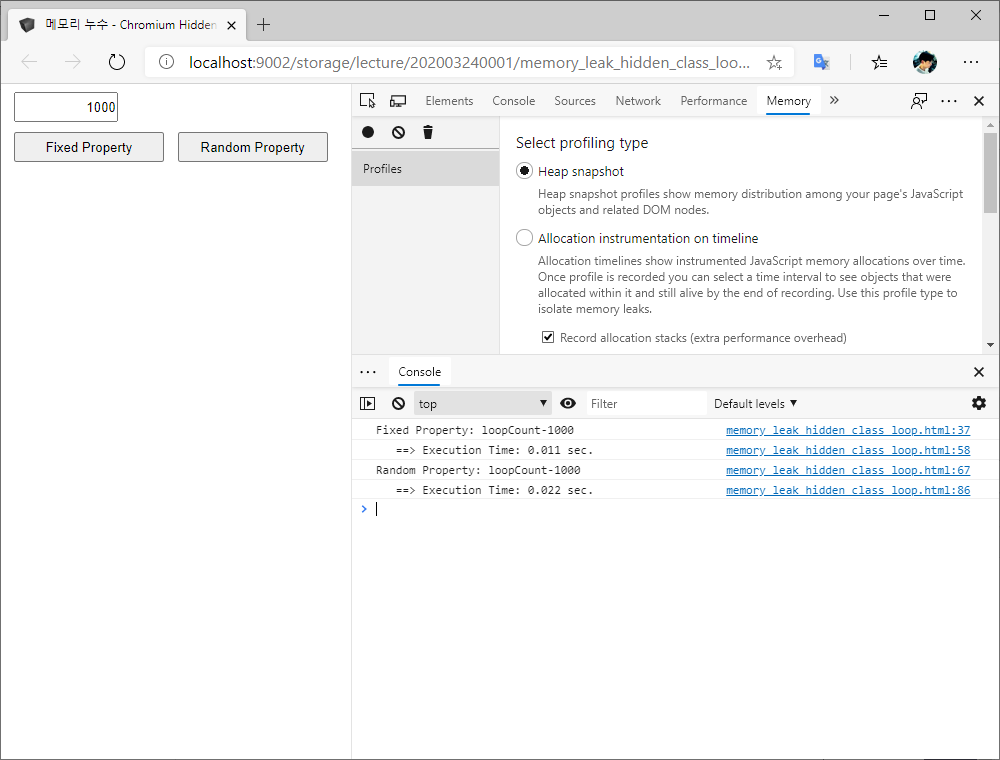
결론적으로 말해서 약간 다른 두 가지 방식으로 대량의 개체를 생성하고 작업에 걸린 시간을 비교하고자 하는 목적의 예제임을 알 수 있습니다.
여기서 한 가지 중요한 점은 두 경우 모두 getRandomString() 함수가 각 속성마다 한 번씩 호출되므로 이로 인한 작업 속도의 차이는 없다는 사실입니다.
두 방식으로 만들어지는 개체를 비교해보면 우선 fnFixedProp() 함수로 만들어지는 개체는 항상 다음 개체 리터럴과 비슷한 구조를 갖게 됩니다.
즉 속성 값은 매번 달라지지만 속성 이름은 항상 동일하며 매번 새로운 개체가 생성될 때마다 모든 속성이 동시에 함께 정의됩니다.
var obj = {
prop0: "{randon_value0}", // 개체 생성 시 모든 속성이 동시에 정의되며 속성 값만 매 반복 시에 설정됩니다.
prop1: "{randon_value1}",
prop2: "{randon_value2}",
prop3: "{randon_value3}",
prop4: "{randon_value4}",
prop5: "{randon_value5}",
prop6: "{randon_value6}",
prop7: "{randon_value7}",
prop8: "{randon_value8}",
prop9: "{randon_value9}"
}
반면 fnRandomProp() 함수로 만들어지는 개체는 다음 개체 리터럴과 비슷한 구조를 갖게 됩니다.
매번 속성 값 뿐만 아니라 속성 이름까지 모두 달라집니다.
또한 최초에는 빈 개체만 생성되었다가 반복문이 수행될 때마다 속성이 하나씩 추가되므로 임의의 두 개체가 동일한 순서로 추가된 동일한 속성 이름을 가질 확률은 거의 없다고 봐도 무방합니다.
var obj = {
prop{randon_value0}: "{randon_value0}", // 첫 번째 반복에서 추가됩니다.
prop{randon_value1}: "{randon_value1}", // 두 번째 반복에서 추가됩니다.
prop{randon_value2}: "{randon_value2}", // 세 번째 반복에서 추가됩니다.
prop{randon_value3}: "{randon_value3}", // 네 번째 반복에서 추가됩니다.
prop{randon_value4}: "{randon_value4}", // 다섯 번째 반복에서 추가됩니다.
prop{randon_value5}: "{randon_value5}", // 여섯 번째 반복에서 추가됩니다.
prop{randon_value6}: "{randon_value6}", // 일곱 번째 반복에서 추가됩니다.
prop{randon_value7}: "{randon_value7}", // 여덟 번째 반복에서 추가됩니다.
prop{randon_value8}: "{randon_value8}", // 아홉 번째 반복에서 추가됩니다.
prop{randon_value9}: "{randon_value9}" // 열 번째 반복에서 추가됩니다.
}이 두 가지 방식 중 어떤 방식이 더 빠르고 느릴지 직접 확인해보고 그 정도와 이유에 이유에 대해서 살펴보도록 하겠습니다.
예제 코드 테스트 결과
다음은 Chromium Edge에서 본문의 예제 HTML 파일을 실행한 결과를 정리한 표와 차트입니다. 반복 횟수가 많아지면 많아질수록 두 방식 간의 수행 속도 차이가 더 확연히 벌어짐을 알 수 있습니다. 반복 횟수가 1,000번일 때는 3배 조금 넘던 수행 속도 차이가 1,000,000번에서는 7배 정도로 벌어집니다.
| 반복 횟수 (Edge) | 1,000 | 5,000 | 10,000 | 50,000 | 100,000 | 500,000 | 1,000,000 |
|---|---|---|---|---|---|---|---|
| Fixed Property | 0.007 sec. | 0.029 sec. | 0.039 sec. | 0.156 sec. | 0.312 sec. | 1.437 sec. | 3.030 sec. |
| Random Property | 0.026 sec. | 0.102 sec. | 0.193 sec. | 0.959 sec. | 1.972 sec. | 10.172 sec. | 21.462 sec. |
반복 횟수에 대한 테스트 구간이 차트로 출력하기에는 조금 부적절하지만, 본문의 주제를 살펴보는 데 있어 중요한 점은 정확한 특정 값이 아니라 전반적인 추세이므로 크게 문제 되지 않습니다.
비교 삼아 IE11에서도 동일한 테스트를 수행해보면 다음과 같은 결과를 보여줍니다.
참고로 fnRandomProp() 함수를 이용한 1,000,000번 반복 테스트에서는 IE11에서 크래시가 발생해서 자동으로 재시작되어 결과 값을 얻을 수 없었습니다.
| 반복 횟수 (IE11) | 1,000 | 5,000 | 10,000 | 50,000 | 100,000 | 500,000 | 1,000,000 |
|---|---|---|---|---|---|---|---|
| Fixed Property | 0.030 sec. | 0.129 sec. | 0.244 sec. | 1.196 sec. | 2.412 sec. | 13.777 sec. | 31.880 sec. |
| Random Property | 0.036 sec. | 0.150 sec. | 0.303 sec. | 1.649 sec. | 3.662 sec. | 26.941 sec. | (no data) |
같은 요령으로 IE11의 결과를 분석해보면 반복 횟수가 1,000번일 때는 수행 속도가 1.2배 정도밖에 차이 나지 않으며 500,000번에서조차 고작 2배가 조금 모자라게 차이 날 뿐입니다. 다시 말하자면 IE11에서도 동일하게 두 방식 간에 수행 속도 차이가 존재하지만 Chromium Edge에서 확인할 수 있는 것만큼 극적인 차이는 아니라는 얘기입니다.
다음과 같이 두 브라우저의 테스트 결과를 한 차트에 겹쳐놓고 살펴보면 그 차이가 더욱 명확하게 두드러집니다.
지금까지의 테스트 결과를 바탕으로 단편적으로나마 다음과 같은 정보를 취합할 수 있습니다.
- 당연한 얘기지만 IE11 보다 Chromium Edge의 작업 성능이 월등함을 정량적인 측정 값을 통해서 다시 한 번 확인할 수 있었습니다.
- 두 브라우저 모두에서 속성을 미리 정의하는 방식으로 작성한 코드의 작업 성능이 훨씬 뛰어나며 특히 Chromium Edge가 보여주는 결과는 매우 인상적입니다. 결론적으로 JavaScript에서는 개체를 정의할 때 당장 사용하지 않더라도 그 수가 너무 많지만 않다면 가급적 미리 모든 속성을 함께 정의하는 습관을 들이는 것이 바람직함을 알 수 있습니다. 사실 이는 다른 많은 JavaScript 최적화 가이드에서 반복적으로 지적하는 사항 중 하나입니다. 다만 본문에서는 실제로 예제를 통해서 그 근거를 함께 제시하고 있을 뿐입니다.
- IE11에서 두 방식 간의 성능 차이 비율이 Chromium Edge에 비해 크지 않은 것은 IE11의 동적 속성 추가 방식이 최적화됐다든지 하는 어떤 긍정적인 이유 때문이 아닙니다. 물론 두 방식 간에 차이점이야 존재하겠지만 오히려 반대로 두 방식 모두 작업 성능이 크게 좋지 않은 와중에 그저 동적 속성 추가 방식의 작업 성능이 조금 더 안 좋을 뿐입니다. 단순히 비율만 보고 IE11의 작업 성능을 긍정적으로 생각하면 안 됩니다.
이렇게 테스트를 통해서 직접 확인한 것처럼 Chromium Edge의 개체 관리 성능이 뛰어난 이유는 바로 V8 엔진의 몇 가지 최적화 기법 때문입니다. 두 가지 개체 생성 방식 간에 큰 작업 성능 차이가 발생하는 원인 또한 이와 직접적으로 관련되어 있습니다. 이어지는 섹션에서는 해당 최적화 기법에 관해 메모리 힙 스냅샷의 관점에서 조금 더 자세히 살펴보도록 하겠습니다.
V8 엔진
2008년, Chrome의 첫 번째 버전과 함께 처음 공개된 Google의 V8은 C++로 개발된 고성능의 오픈 소스 JavaScript/WebAssembly 엔진입니다. V8 엔진은 독립적으로 실행할 수도 있지만, 그보다는 다른 C++ 응용 프로그램에 포함시켜서 사용하는 경우가 많습니다.
대표적인 사례로 Google Chrome을 비롯한 Microsoft Chromium Edge, Opera, Brave, Vivaldi 등의 Chromium 계열의 브라우저에서 JavaScript/WebAssembly 엔진으로 사용되고 있고, JavaScript 기반의 소프트웨어 플랫폼인 Node.js의 런타임 환경이기도 합니다. 그 밖에도 Couchbase, MongoDB 같은 NoSql 데이터베이스 제품에서도 사용되며, 크로스 플랫폼 데스크톱 응용 프로그램 프레임워크인 Electron을 비롯하여 그 외 다양한 분야에서 활발하게 사용되고 있습니다.
그 자체만으로도 V8 엔진은 다양한 기술적 주제를 포괄하는 또 다른 방대한 생태계를 갖고 있습니다. 본문에서는 그중에서도 V8 엔진의 여러 가지 최적화 기법 중 시리즈의 주제인 메모리 힙 스냅샷의 관점에서 분석 가능한 극히 일부 영역에 대해서만 보다 집중적으로 살펴봅니다. 그 외에 다른 최적화 기법들에 관해서는 간단하게 소개 정도로만 언급하고 넘어가도록 하겠습니다. V8 엔진에 대한 보다 자세한 정보는 다음 링크의 문서 및 소스를 참고하시기 바랍니다.
V8 엔진의 최적화 기법
다소 과장을 더해서 V8 엔진이 만들어지게 된 근본적인 배경을 웹 브라우저상에서 JavaScript의 실행 속도를 최대한 끌어올리기 위함이라고 말해도 큰 무리는 없을 것입니다. (모든 JavaScript 엔진의 공통적인 목표이기도 합니다.) 태생 자체가 이렇다 보니 엔진 내부적으로 다양한 최적화 기법이 사용됩니다. 그뿐만 아니라 첫 번째 버전이 등장한 이후로도 계속 변화해온 JavaScript의 신기술 및 개선 사항에 대해서도 최적화와 관련된 지속적인 대응이 이루어지고 있습니다. 인터넷에서 V8 엔진의 최적화 기법을 소개하는 다양한 문서들을 찾아볼 수 있지만, 개인적으로는 다음 문서가 관련 내용을 초보 개발자의 입장에서 가장 친절하게 설명하고 있다고 생각합니다.
- How JavaScript works: inside the V8 engine + 5 tips on how to write optimized code | SessionStack Blog
- 자바스크립트는 어떻게 작동하는가: V8 엔진의 내부 + 최적화된 코드를 작성을 위한 다섯 가지 팁 | Huiseoul Engineering (위 문서의 개인 번역본)
JavaScript 실행 파이프라인
2020년 3월 현재, 최신 버전의 V8 엔진에서는 인터프리터인 Ignition 및 최적화 컴파일러인 TurboFan을 기반으로 JavaScript 실행 파이프라인이 구성됩니다. 과거 버전에서는 비슷한 역할을 각각 Full-codegen과 Crankshaft라는 컴파일러가 담당했었으나 이 두 컴파일러는 V8 엔진 버전 5.9 (Chrome 버전 59) 이후로는 더 이상 사용되지 않습니다. 근본적인 작업 흐름에 큰 차이는 없지만 두 쌍의 인터프리터/컴파일러 간에 세부적으로 미묘하게 다른 점들이 존재하므로 관련 문서를 읽을 때 주의하시기 바랍니다. Ignition과 TurboFan이 등장한 이유가 Full-codegen과 Crankshaft를 대체 및 개선하기 위함이므로 이는 어떤 면에서는 당연한 얘기입니다.
웹 페이지의 JavaScript 실행 과정을 간단하게 살펴보면, 먼저 페이지가 로드되고 JavaScript 코드가 파서를 거쳐 인터프리터인 Ignition을 통해서 바이트코드로 변환되어 우선 실행됩니다. 그와 동시에 다른 스레드에서는 실행되고 있는 바이트코드를 프로파일링하고 있다가 최적화가 필요하다고 판단되는 코드(주로 반복적으로 사용되는 코드)를 최적화 컴파일러인 TurboFan으로 전달하여 다시 고도로 최적화하여 컴파일하는 식입니다.
다시 말하자면 비록 최적화 수준은 다소 부족하더라도 일단 페이지가 로드되자마자 최대한 빨리 변환된 바이트코드부터 실행하여 브라우저 사용자에 대한 응답성을 높이고, 다른 한쪽에서는 그렇게 실행된 바이트코드를 지켜보고 있다가 기회가 될 때마다 부족한 최적화를 강화하여 보완하는 방식으로, 비록 세부 구현 상세는 다르더라도 대부분의 최신 JavaScript 엔진들이 공통적으로 취하는 패턴이기도 합니다. 또한 이후에 언급할 다른 최적화 기법들은 대부분 이 과정 중에 수행되는 작업입니다.
그러나 이 설명은 어디까지나 C++ 같은 언어를 이해하지 못하는 웹 클라이언트 개발자의 입장에서 이해를 돕기 위해 최대한 간단하게 정리한 것으로 실제로 이 과정 중에 벌어지는 작업은 훨씬 더 복잡합니다. 따라서 일단 여기에서는 대략적인 개념만 이해하시기 바랍니다. V8 엔진의 JavaScript 실행 파이프라인에 관한 더 자세한 정보는 앞에서 소개한 문서와 다음 문서들을 참고하시기 바랍니다.
- Launching Ignition and TurboFan | V8 JavaScript engine
- JavaScript engine fundamentals: Shapes and Inline Caches | Mathias Bynens
- JavaScript engine fundamentals: Shapes and Inline Caches | First Blog (위 문서의 개인 번역본)
- V8 엔진은 어떻게 내 코드를 실행하는 걸까? | Evan's Tech Blog
- javascript v8 엔진의 변경내용 및 Node.js 적용 | kern의 FE-Note
인라이닝(Inlining)
인라이닝은 함수 호출 사이트(함수 호출 위치)를 호출된 함수의 본문으로 대체하는 일반적인 최적화 기법입니다.
기본적인 개념은 아주 단순합니다.
가령 다음과 같이 간단한 두 함수가 정의되어 있다고 가정해보겠습니다.
평범하게 fnLoop() 함수가 fnDouble() 함수를 반복적으로 호출하는 구조입니다.
function fnDouble(x) {
return x * 2;
}
function fnLoop(count) {
var result = 0;
for (var i = 0; i < count; i++) {
result += fnDouble(i);
}
return result;
}
이 코드를 대상으로 인라이닝을 수행한 결과는 다음과 비슷할 것입니다.
즉 fnDouble() 함수를 호출하는 코드가 해당 함수의 본문으로 대체됩니다.
물론 이 코드는 어디까지나 이해를 돕기 위해서 임의로 만든 예시일 뿐입니다.
인라이닝은 V8 엔진에서만 사용되는 최적화 기법도 아니고, 이 예시처럼 코드 원본을 대상으로 수행되는 작업도 아니라는 점에 주의하시기 바랍니다.
어떤 면에서는 재미있는 점이 코드 수준에서 개발자가 리팩터링을 열심해 해놨더니 컴파일러가 다시 열심히 복사 및 붙여넣기로 바꾸고 있는 셈입니다.
function fnLoop(count) {
var result = 0;
for (var i = 0; i < count; i++) {
result += i * 2;
}
return result;
}인라이닝은 농담삼아 '모든 최적화의 어머니'라고 부르는 사람이 있을 정도로 보편적인 최적화 기법이지만 그 결과가 성능에 미치는 영향은 조금 미묘합니다. 가령 이렇게 함수 호출이 제거되고 나면 당연히 함수를 호출하기 위해서 필요로 했던 비용이 줄어들게 됩니다. 예를 들어 스택이나 레지스터 수준에서 매개 변수 및 반환 값 등을 주고받기 위해 필요로 했던 명령들이 불필요해지고, 따라서 자연스럽게 성능이 개선됩니다. 그러나 한편으로는 요즘처럼 하드웨어의 성능이 극도로 발달한 환경에서 인라이닝으로 향상되는 수준의 성능 개선이 큰 의미가 있을지 의문이기도 합니다.
그 외에도 생각해볼 만한 점이 몇 가지 더 있습니다. 바로 어떤 조건을 만족하는 함수를 대상으로 인라이닝 해야 하는지가 관건입니다. 당연한 얘기지만 코드 전체에서 한두 번 정도 호출되는 함수보다는 위의 예시처럼 반복적으로 호출되는 함수를 인라이닝 하는 것이 더 효과적일 것입니다.
또한 호출되는 함수의 본문 크기도 중요합니다. 예시의 함수는 단 한 줄짜리 함수지만, 실무에서는 수십 또는 수백 줄짜리 함수도 어렵지 않게 찾아볼 수 있습니다. 인라이닝은 공간 비용을 투자해서 성능 비용에서 이점을 얻는 최적화 기법입니다. 인라이닝이 적용된 바이너리는 인라이닝이 적용되지 않은 바이너리보다 거의 반드시 크기가 더 커집니다. 그런데 만약 500줄짜리 함수를 호출하는 1000곳의 함수 호출 사이트를 모두 인라이닝 한다면 그 결과가 긍정적일지는 의문입니다. .exe 파일이나 .dll 파일을 컴파일하는 환경에서는 요즘처럼 저장 공간이 풍부한 시대에 큰 문제가 되지 않겠지만 우리가 작업하는 환경은 웹 브라우저라는 사실을 잊지 말아야 합니다.
다행스럽게도 인라이닝 적용 여부 및 대상 함수에 대한 모든 판단은 앞에서 언급했던 TurboFan이 (예전에는 Crankshaft가) 대신해줍니다.
인라이닝 최적화를 통해서 얻을 수 있는 진정한 이점은 그 결과를 바탕으로 다른 추가적인 최적화가 용이해진다는 점입니다. 복잡한 설명을 덧붙이지 않더라도 여러 개의 함수로 쪼개져 있는 코드보다는 하나로 합쳐진 상대적으로 적은 수의 함수 본문을 대상으로 최적화를 수행하는 것이 훨씬 용이할 것이라는 사실은 쉽게 짐작할 수 있을 것입니다. 인라이닝 최적화에 대한 더 자세한 정보는 다음 문서들을 참고하시기 바랍니다.
- 인라인 확장 | 위키백과, 우리 모두의 백과사전
- Inline expansion - Wikipedia
- TurboFan Inlining
- TurboFan Inlining Heuristics
Chromium Edge에서 V8 엔진의 인라이닝 정보 살펴보기
일반적으로 V8 엔진이 동작하는 상태를 살펴보기 위해서는 소스를 다운로드 받고 빌드해서 독립적으로 실행할 수 있는 환경을 구성해야 합니다. V8 엔진이 자체적으로 제공하는 D8이라는 디버그 쉘을 사용해야 하는데, 일반적인 웹 클라이언트 개발자의 입장에서는 이런 환경을 구성하기가 쉽지 않습니다.
대신 Chromium 계열의 브라우저에서는 --js-flags 명령줄 스위치를 활용하여 비슷한 방식으로 V8 엔진의 정보를 살펴볼 수 있는 방법이 지원됩니다.
그러나 아쉽게도 Windows 환경에서는 이 방법 역시 한 가지 문제점을 안고 있습니다.
당연한 얘기지만 Windows 환경에서 실행되는 Chromium 계열의 브라우저는 GUI 응용 프로그램입니다.
바로 그 때문에 콘솔 stdout에 추적 정보를 출력할 수가 없어서 인터넷상의 가이드대로 따라해 봐도 추적 정보가 출력되지 않습니다.
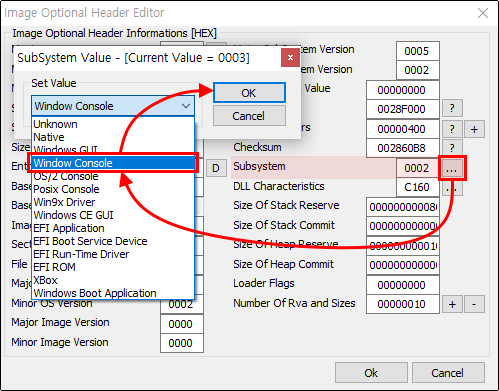
이러한 문제점을 해결하기 위해서는 브라우저의 실행 파일을 HEX 편집기 등으로 직접 편집해서 PE 헤더의 Subsystem 필드의 값을 IMAGE_SUBSYSTEM_WINDOWS_GUI(2)에서 WINDOWS_SUBSYSTEM_WINDOWS_CUI(3)으로 변경해줘야 합니다.
만약을 위해서 작업을 계속 진행하기 전에 먼저 실행 파일의 백업본을 저장하여 언제라도 복구할 수 있도록 준비해놓으시기 바랍니다.
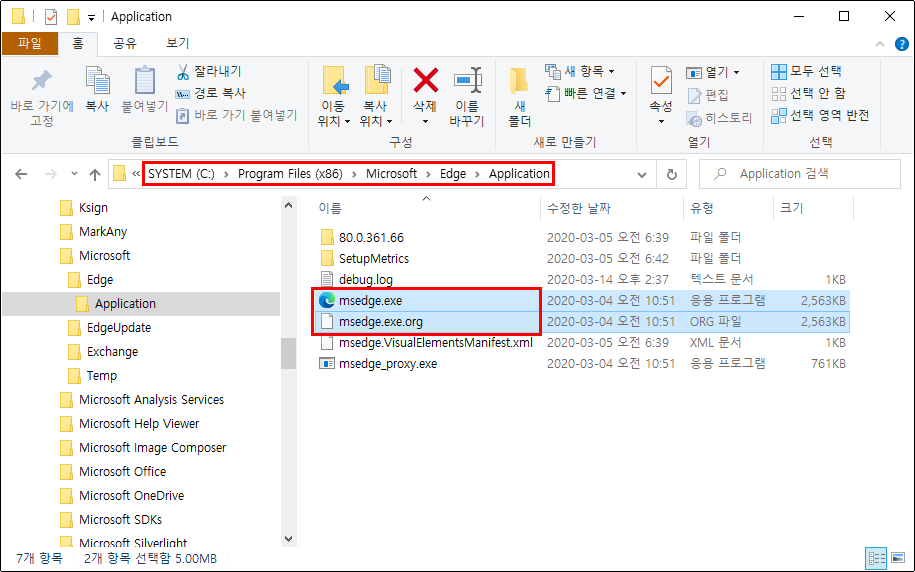
다음으로 실행 파일을 편집할 수 있는 도구가 필요합니다. PE 헤더의 구조에 능통하고 HEX 편집기에 익숙하신 분은 직접 필드 위치를 찾아서 수정하셔도 무방하지만 그보다는 약간 간편한 도구를 사용하도록 하겠습니다. 다른 유틸리티 프로그램들도 많지만 제가 추천하는 도구는 PE Tools로, 최신 버전을 다운로드 받아 편한 위치에 압축을 풉니다. 관리자 권한으로 PE Tools를 실행한 다음, Tool 메뉴 하위의 PE Editor 항목을 선택합니다.
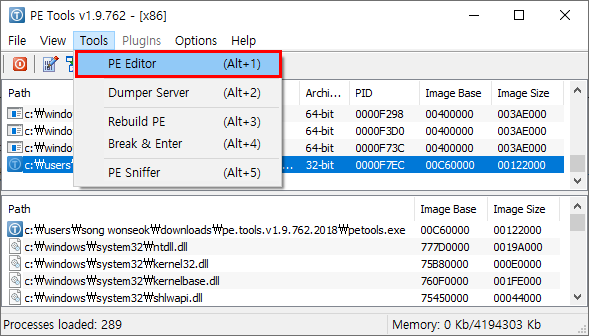
그러면 편집할 파일을 선택하는 열기 대화 상자가 나타나는데, 방금 백업본을 만들어두었던 msedge.exe 파일을 선택하면 PE Editor 대화 상자가 나타납니다.
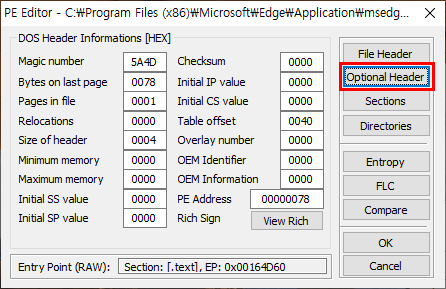
대화 상자 우측의 Optional Header 버튼을 클릭하면 다시 Image Optional Header Information 대화 상자가 나타납니다.
마지막으로 이 대화 상자에서 값이 0002로 지정되어 있는 Subsystem 항목 우측의 버튼을 클릭해서 Windows Console 항목을 선택하고 계속 Ok 버튼을 누른 다음, 프로그램을 종료하면 됩니다.
이제 PE 헤더가 변경된 Chromium Edge에 --js-flags 명령줄 스위치를 지정하여 실행해 보겠습니다.
명령 프롬프트를 관리자 권한으로 실행하고 Chromium Edge가 설치된 폴더로 이동한 다음, 아래와 같이 명령을 입력합니다.
여기서 --trace-turbo-inlining 플래그가 바로 인라이닝 정보를 살펴보겠다는 뜻입니다.
간혹 오래된 문서를 읽다보면 --trace-inlining 플래그에 관해서 설명하고 있는 경우가 있는데 이 플래그는 Crankshaft에 대응하는 플래그이므로 참고하시기 바랍니다.
msedge.exe --no-sandbox --js-flags="--trace-turbo-inlining"
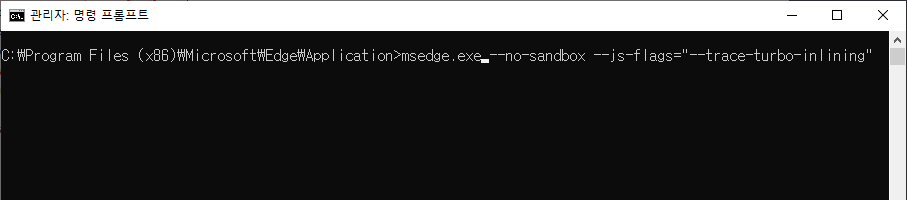
그러면 다음과 같이 최초의 명령 프롬프트 외에 Chromium Edge와 함께 또 하나의 명령 프롬프트가 실행됩니다.
또한 Chromium Edge 상단에는 --no-sandbox 플래그 사용에 대한 경고가 함께 나타납니다.
자세히 보시면 새 명령 프롬프트 창의 아이콘이 Chromium Edge의 아이콘임을 확인할 수 있습니다.
이제 이 상태에서 본문의 예제 HTML 파일로 이동합니다.
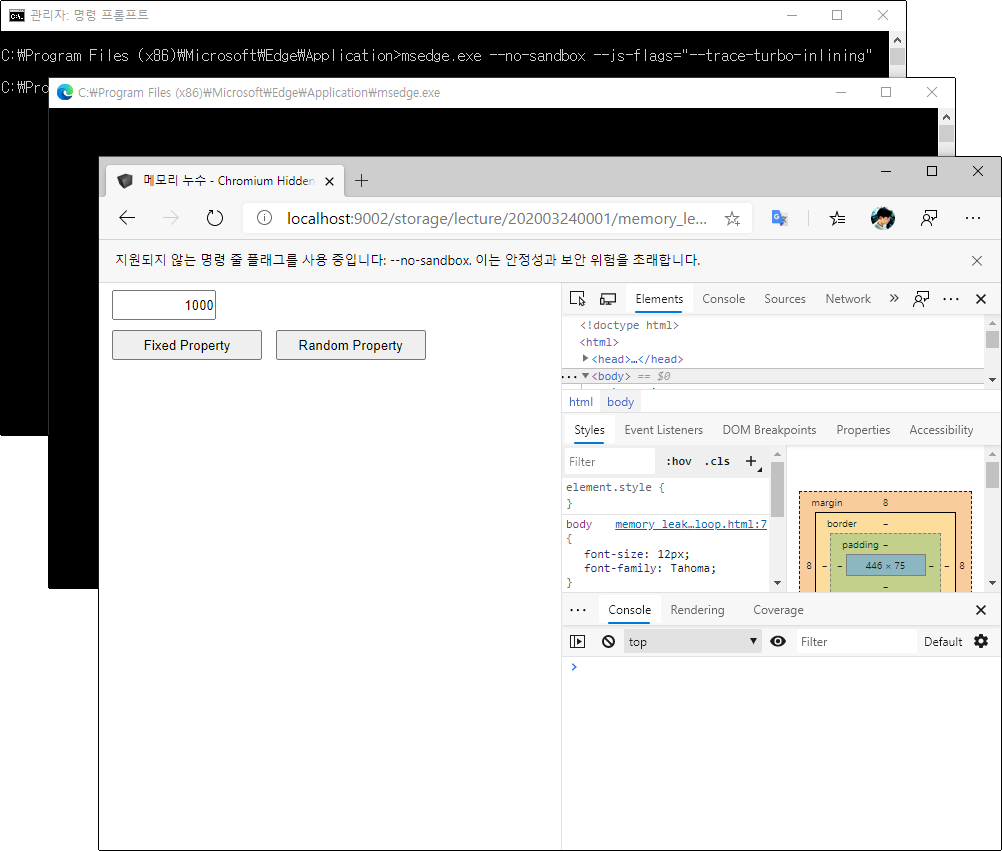
먼저 현재 상태 그대로 Fixed Property 버튼을 클릭해보면 다음과 같은 추적 로그가 나타납니다.
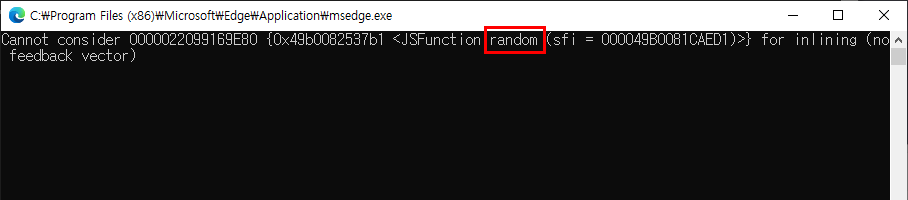
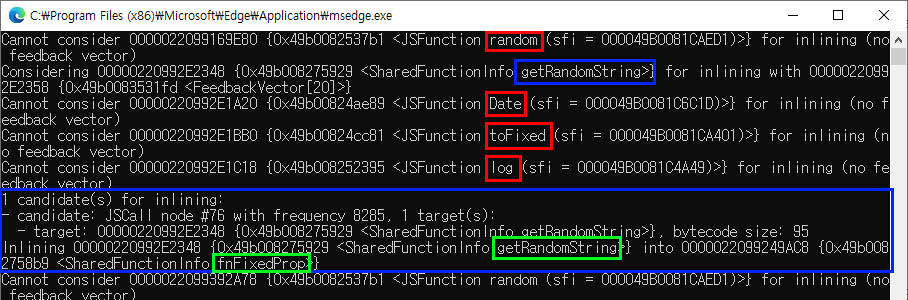
이 로그를 나름대로 해석해보자면 Math.random() 함수를 인라이닝 대상으로 검토해봤으나 특정 조건을 만족하지 않아서 인라이닝 하지 않았다는 뜻으로 해석해도 무리가 없을 것 같습니다.
다른 함수들에 대한 언급은 없으며 참고로 현재 조건에서 random() 함수는 1000 x 10 x 4회로 가장 많이 호출되는 함수 중 하나입니다.
이번에는 반복 횟수를 100,000번으로 높이고 Fixed Property 버튼을 클릭합니다.
그 결과는 다음과 같습니다.
반복 횟수가 100배 늘어남으로 인해서 random() 함수 외에도 getRandomString(), Date(), toFixed(), log() 함수가 인라이닝 대상으로 검토되었으나 getRandomString() 함수 외에는 모두 조건을 만족하지 못했습니다.
그리고 결과적으로 getRandomString() 함수 하나만 fnFixedProp() 함수에 인라이닝 되었음을 확인할 수 있습니다.
사실 이번 예제에서 조건을 만족하지 못한 함수들은 모두 JavaScript가 기본 제공하는 함수라는 점을 감안해보면 당연한 결과일런지도 모르겠습니다.
모든 검토를 마쳤으면 변경된 실행 파일의 확장자를 수정하여 보관하고 원본 실행 파일을 복구하여 다시 정상적인 상태로 되돌립니다.
지금까지 살펴본 방법과 같은 요령으로 V8 엔진의 다른 다양한 내부 정보를 살펴볼 수 있으며, --trace-inlining 외의 다른 플래그들에 대한 더 자세한 정보는 다음 링크들을 참고하시기 바랍니다.
여기서 주의해야 할 점은 Chromium 계열의 브라우저에 전달되는 플래그와 --js-flags 명령줄 스위치를 통해서 V8 엔진으로 전달되는 플래그가 서로 다르다는 점입니다.
노트
PE 헤더의 Subsystem 필드 값을 WINDOWS_SUBSYSTEM_WINDOWS_CUI(3)으로 변경한 실행 파일의 동작에서
Chromium Edge (테스트에 사용한 버전 80.0.361.66) 및 Chrome (테스트에 사용한 버전 80.0.3987.132) 간에 약간의 차이가 존재합니다.
Chrome에서는 방금 살펴본 것과는 달리 새로운 명령 프롬프트 창이 추가로 나타나지 않고 처음 관리자 권한으로 실행한 명령 프롬프트 창에서 추적 로그가 출력됩니다.
그러나 두 브라우저 모두 앞으로도 지금과 동일하게 작동할 것이라고 장담 드릴 수는 없습니다.
또한 이런 방식으로 출력한 추적 로그와 D8 또는 Node.js 등으로 출력한 로그가 완전히 똑같지는 않습니다.
Chromium 계열의 브라우저에서 --js-flags 스위치를 지정하여 출력한 로그에 누락된 내용이 존재하는 경우가 종종 있고 동작하지 않는 플래그도 제법 있으므로 참고하시기 바랍니다.
히든 클래스(Hidden class)
드디어 히든 클래스에 대해 언급할 수 있는 단계까지 도달했습니다. 우선 본문에서는 히든 클래스의 개념 자체를 이해하는 데 중점을 두고, 메모리 힙 스냅샷 관련 내용도 그에 준하는 수준까지만 다룰 것입니다. 그런 다음 이어지는 글에서는 메모리 힙 스냅샷을 통해서 V8 엔진이 JavaScript 개체를 관리하는 방법에 대해 최대한 자세하게 살펴보도록 하겠습니다. 먼저 히든 클래스가 무엇인지부터 알아보겠습니다.
동적 언어와 정적 언어 간의 가장 큰 차이점 중 하나는 런타임에 개체의 형식을 변경할 수 있는지 여부입니다. 여기서 개체 형식을 변경한다는 말의 뜻은 형변환 같은 것을 얘기하는 것이 아니라 개체의 정의 자체를 변경하는 것을 의미합니다. JavaScript 역시 동적 언어이므로 다음 코드와 같이 런타임에 개체 형식을 간단하게 변경할 수 있습니다. 익히 알고 계신 것처럼 사실 JavaScript에서 이런 패턴의 코드는 너무나도 일상적이어서 특별히 의식하지 않고 사용되는 수준입니다.
var obj = {
x: 10,
y: 10
};
obj.z = 10; // obj 개체의 형식을 변경합니다.
만약 이런 패턴의 코드를 C/C++이나 C#, Java 등과 같은 정적 언어에서 작성한다면 컴파일하기도 전에 이미 통합 개발 환경에서 경고부터 받을 것입니다. 그래서 정적 언어에서는 반대로 개발자의 편의를 위해 C#의 확장 메서드 등과 같은 다양한 부가적인 기능을 문법적 설탕(Syntactic sugar)으로 제공해주기도 합니다. 그러나 세상에 공짜는 없는 법이고 동적 언어의 이런 편리한 기능들은 무언가를 희생하고 얻은 대가인 경우가 대부분입니다. 그리고 거의 항상 그 희생양은 성능입니다.
메모리 주소 같은 어려운 용어는 최대한 배제하고 런타임 시 형식 변경 측면에서 동적 언어의 특징을 검토해보겠습니다.
직접 살펴본 것과 같이 동적 언어에서는 편리하게 런타임에 속성을 추가하거나 제거할 수 있습니다.
더군다나 JavaScript에서는 모든 것이 개체이기 때문에 function, 즉 메서드까지도 언제든지 추가 또는 제거 가능합니다.
그러나 이 얘기를 반대로 생각해보면 실제로 프로그램을 실행하기 전까지는 개체의 형식을 전혀 예측할 수 없다는 뜻이기도 합니다. 특정 개체의 특정 속성 값을 읽고 쓰기 위해서는, 또는 메서드를 실행하기 위해서는 먼저 해당 속성에 접근부터 해야 하는데 속성 값이 저장된 위치는 커녕 뚜껑을 열어보기 전까지는 해당 속성의 존재 여부조차도 알 수 없습니다. 더 큰 문제는 이런 상황이 한 번만 벌어지는 것이 아니라는 점입니다. 이전에 정상적으로 접근했던 속성에 다시 접근하는 경우라도 이미 그 사이에 속성이 제거되었을 수도 있기 때문입니다.
결론적으로 특정 속성에 접근하기 위해서는 매번 개체의 속성들을 뒤져봐야만 한다는 뜻이 되고, 이는 컴파일 시점부터 이미 개체가 가진 속성들에 대한 메타 정보를 확보하고 있는 정적 언어에 비해 성능이 떨어지는 가장 주된 이유 중 하나로 작용합니다. 따라서 대부분의 동적 언어는 이런 문제점을 보완하기 위한 나름의 메커니즘을 갖고 있으며, 언어 자체는 아니지만 V8 엔진의 경우에는 히든 클래스가 바로 그런 역할을 합니다.
의외로 히든 클래스의 아이디어 자체는 매우 단순합니다. 개체 자체에 속성에 관한 메타 정보가 없다면 조금 귀찮기는 하지만 엔진 수준에서 직접 따로 하나를 만들어서 같이 가지고 다니겠다는 것입니다. 조금 더 구체적으로 말하자면 동적 언어인 JavaScript의 언어 사양에 속성 관련 메타 정보가 없어서 V8 엔진이 직접 관리하는 속성 관련 메타 정보, 그것이 바로 히든 클래스(Hidden class)입니다. 물론 그 실제 구현까지 지금 설명처럼 간단하지는 않습니다. 그래서 이 부분에 관해서는 다음 글에서 별도로 상세하게 살펴보고자 합니다.
그러나 다시 한번 드리는 말이지만, 세상에 공짜는 없는 법입니다. 얼핏 듣기에는 히든 클래스를 도입하기만 하면 모든 문제가 해결될 것 같지만 반드시 그런 것만은 아닙니다. 그냥 단순하게만 생각해봐도 우선 히든 클래스의 크키만큼 메모리 사용량이 늘어날 수밖에 없습니다. 또한, 결과적으로는 속성을 찾기 위해서 거쳐야 할 단계가 또 하나 늘어난 것으로 생각할 수도 있습니다. 따라서 히든 클래스의 이점을 최대한 얻기 위해서는 코드를 작성할 때 몇 가지 점들에 주의해야만 합니다.
그렇습니다. 어쩌면 이미 눈치채신 분들도 계시겠지만, 본문의 예제 HTML 파일이 바로 히든 클래스를 활용하도록 작성한 코드와 그렇지 않은 코드 간의 성능을 비교하기 위한 목적을 갖고 있는 예제입니다.
메모리 힙 스냅샷으로 히든 클래스 살펴보기
가장 먼저 기억해야 할 점은 JavaScript 개체뿐만 아니라 V8 엔진에서 힙 메모리에 존재하는 가비지 컬렉터가 관리하는 모든 개체의 첫 번째 필드는 히든 클래스를 가리킨다는 사실입니다. 결국 여러분은 지금까지 두 편의 시리즈를 읽어보면서 이미 히든 클래스를 여러 차례 눈으로 보고서도 지나친 셈입니다. 가령 다음은 Console 창으로 간단한 개체를 선언하고 이를 메모리 힙 스냅샷으로 살펴본 모습입니다.
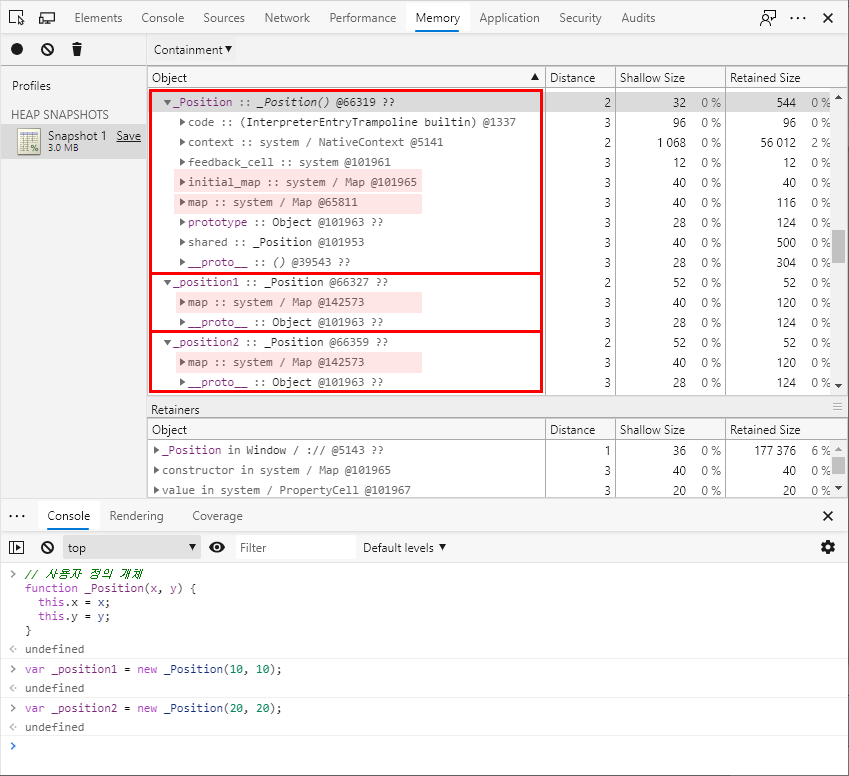
대부분 예상하고 계신 것처럼 각 개체에 공통적으로 존재하는 map 필드가 바로 히든 클래스입니다.
참고로 _Position 개체에는 initial_map이라는 별도의 필드가 하나 더 존재하는데 이에 관해서는 잠시 후에 다시 살펴보도록 하겠습니다.
일단 여기서 주의 깊게 살펴봐야 할 부분은 _position1 개체 및 _position2 개체의 히든 클래스가 동일한 @142573 개체를 가리킨다는 점입니다.
그 이유는 두 개체 인스턴스가 같은 생성자를 기반으로 만들어졌으며 동일한 속성을 동일한 순서로 갖고 있기 때문입니다.
사실 이 한 문장 안에 히든 클래스의 중요한 특징들이 모두 담겨 있지만, 우선 지금은 한 가지씩 천천히 살펴보도록 하겠습니다.
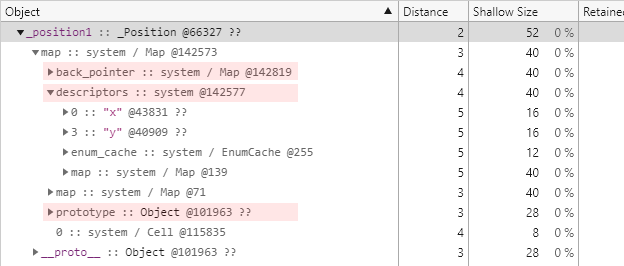
_position1 개체의 map 필드를 확장해보면 다음과 같은 하위 필드들을 확인할 수 있습니다.
몇 가지 필드가 눈에 띄는데 각 필드들의 역할을 간단히 정리해보면 다음과 같습니다.
| 필드 이름 | 역할 |
|---|---|
| back_pointer | 현재 히든 클래스가 어떤 히든 클래스로부터 파생됐는지를 가리킵니다. 개체 지향 프로그래밍식으로 말하자면 부모 클래스를 가리키는 셈입니다. |
| descriptors | 개체의 대부분의 속성들에 관한 메타 정보가 저장됩니다. 이에 관해서는 이어지는 다음 글에서 보다 자세히 살펴봅니다. |
| prototype |
개체의 __proto__ 속성과 동일한 개체를 참조합니다.
|
| transition |
back_pointer 필드와는 반대로 현재 히든 클래스가 어떤 히든 클래스로 전환되는지를 가리킵니다.
(잠시 후 다른 스냅샷에서 확인할 수 있습니다.)
|
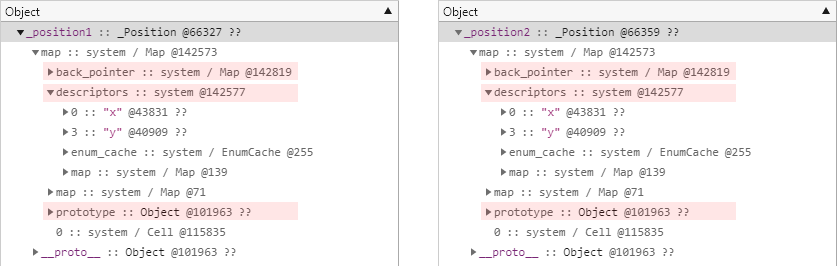
지금으로서는 _position1 개체와 _position2 개체 간에 별다른 차이가 없기 때문에 히든 클래스의 내용도 크게 다르지 않습니다.
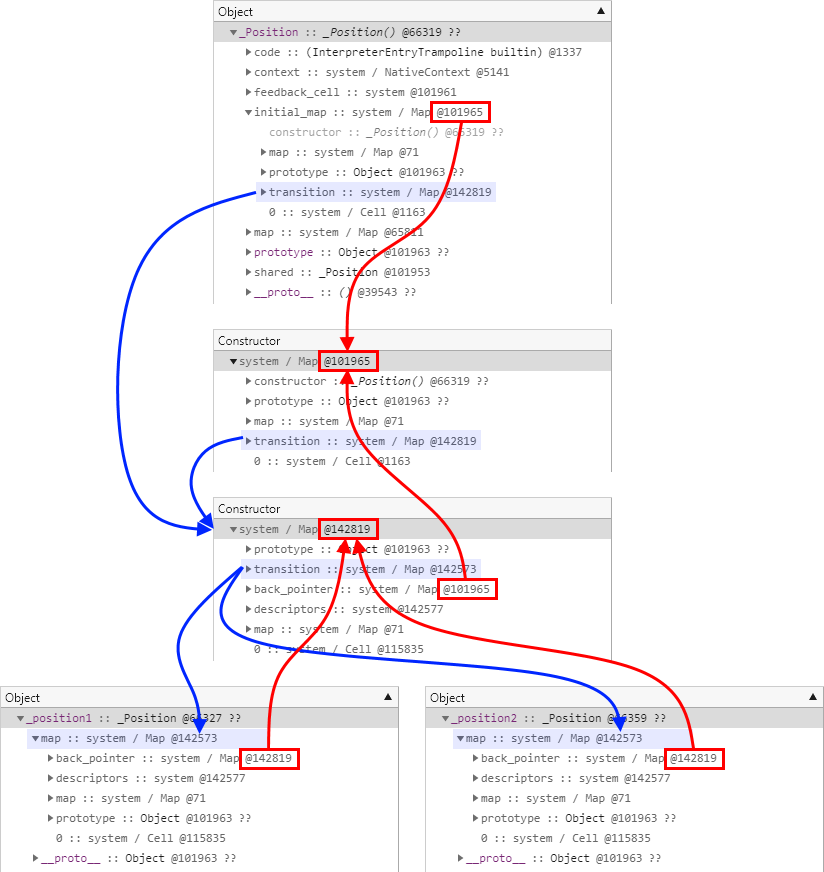
다음은 두 개체의 히든 클래스 정보를 비교하기 쉽게 편집한 모습입니다.
사실상 이 그림에는 나타나지 않는 각 인스턴스의 속성 값들 외에는 다른 부분이 없습니다.
계속해서 이번에는 히든 클래스들 간의 계층 구조를 파악해보겠습니다.
_position1 개체의 히든 클래스에서 back_pointer 필드를 마우스 오른쪽 버튼으로 클릭한 다음, 메뉴에서 Reveal In Summary view 항목을 선택합니다.
그러면 첫 번째 글에서 설명했던 것처럼 Containment 보기가 열리면서 대상 개체로 바로 이동합니다.
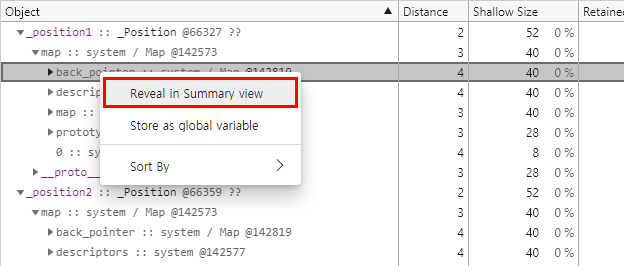
그렇게 해서 찾은 개체가 다음과 같은 @142819 개체입니다.
_position1 개체와 _position2 개체의 히든 클래스에서 확인할 수 있었던 속성들에 관한 메타 정보가 어디로부터 온 것인지 알 수 있습니다.
다시 한번 back_pointer 필드를 이용해서 한 단계 더 위의 히든 클래스를 찾아보겠습니다.
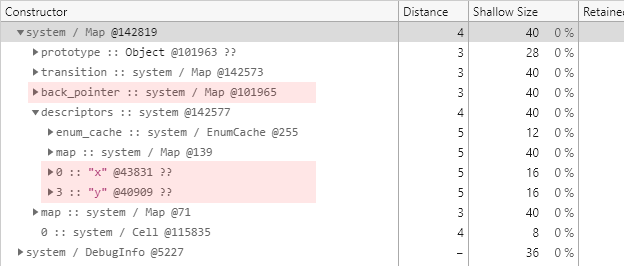
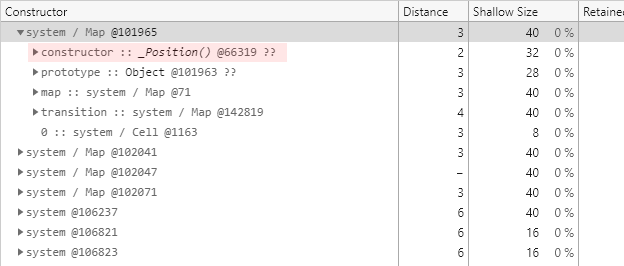
다음은 그렇게 찾은 @101965 개체입니다.
그런데 이번에는 제공되는 필드가 지금까지와는 뭔가 다릅니다.
일단 descriptors 필드가 존재하지 않습니다.
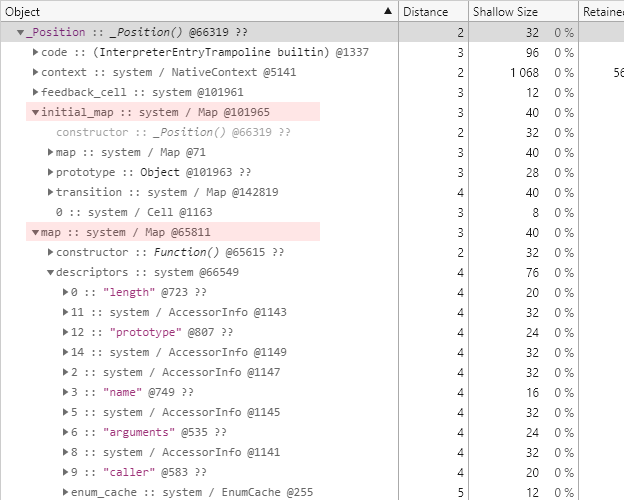
그리고 지금까지는 볼 수 없었던 constructor 필드가 존재하는데, 그 형식이 매우 친숙한 _Position() 입니다.
다시 _Position() 개체로 이동해보면 initial_map 필드가 바로 @101965 개체임을 확인할 수 있습니다.
그뿐만 아니라 map 필드 하위의 descriptors 필드를 주의 깊게 살펴보면 이 개체의 히든 클래스는 너무도 당연한 얘기지만 Function() 형식에 대한 히든 클래스임을 확인할 수 있습니다.
다음은 지금까지 살펴본 히든 클래스들의 계층 구조를 살펴보기 편하도록 다시 정리한 결과입니다.
붉은색 화살표로 표시된 back_pointer 필드를 따라서 개체를 추적해보면 히든 클래스가 대략 어떠한 형태로 연결되는지 이해하실 수 있을 것입니다.
반대로 파란 배경색의 transition 필드를 따라서 개체를 추적해보면 전환 정보에 따른 연결 상태를 확인하실 수도 있습니다.
그렇다면 이번에는 Console 창에 다음과 같은 코드를 추가로 입력하여 _position2 개체에 z라는 이름의 속성을 추가해보겠습니다.
이는 _position2 개체의 형식이 변경되는 결과를 가져옵니다.
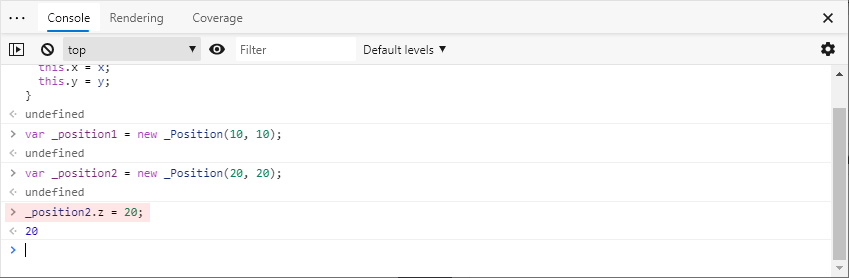
다음은 다시 메모리 힙 스냅샷을 찍고 _position1 개체와 _position2 개체를 살펴본 모습입니다.
이번에도 정보를 비교하기 쉽게 편집했는데, 상당히 흥미로운 변화가 발생했음을 확인할 수 있습니다.
여전히 _position1 개체의 히든 클래스 필드는 전과 동일한 개체를 참조하는 반면, 새롭게 속성을 추가한 _position2 개체의 히든 클래스 필드는 참조하는 개체가 변경되었습니다.
이 새로운 히든 클래스 @142941 개체는 back_pointer 필드를 통해서 기존의 히든 클래스인 @142573 개체로 연결됩니다.
반대로 _position1 개체의 히든 클래스에도 새롭게 transition 필드가 추가되어 @142941 개체를 참조하여 전환 정보를 관리합니다.
다시 말해서 V8 엔진이 개체의 속성 변경에 따른 히든 클래스의 전환 추이를 모두 파악하고 있는 셈입니다.
지금까지 살펴본 것처럼 V8 엔진은 개체에 속성이 추가되는 등의 변경이 발생할 때마다 히든 클래스의 정보를 관리하여 속성에 접근하는 속도를 개선하기 위한 메타 정보를 유지합니다.
그러나 실제로 발생할 수 있는 상황은 본문의 예시보다 훨씬 복잡하며, 당연히 V8 엔진이 대응하는 방식도 매우 다양합니다.
가령 _position1 개체에 전혀 새로운 이름으로 속성을 또 추가한다면 이번엔 어떻게 될까요?
이번에도 새로운 히든 클래스 필드가 만들어질까요?
결론만 말씀드리면 그렇지 않습니다.
대신 새로운 descriptors 개체가 만들어집니다.
게다가 V8 엔진 자체가 여전히 활발하게 개선되고 있는 그야말로 생명력 넘치는 제품이기 때문에 이후로도 미묘한 부분까지 본문의 내용이 완벽하게 일치할 것이라고는 장담할 수 없습니다.
따라서 단편적인 지식만 기억하는 것보다는 이번 섹션에서 살펴본 것처럼 직접 히든 클래스의 구조를 찾아볼 수 있는 방법을 익히는 것이 중요합니다.
만약 히든 클래스에 대한 본문의 설명이 어렵게 느껴지거나 메모리 힙 스냅샷을 활용해서 히든 클래스의 구조를 자세하게 살펴보는 방법에 별다른 관심이 없다면 다음 문서를 참고하시기 바랍니다.
마지막으로 본문의 예제 HTML 파일에서 히든 클래스가 어떠한 형태로 만들어지는지를 확인해보고 다음 섹션으로 넘어가도록 하겠습니다.
지금까지 살펴본 내용을 어느 정도 이해했다면 그 결과를 충분히 예상하실 수 있을 것입니다.
다만 그 전에 예제 HTML 파일의 코드를 약간 변경해야 합니다.
지금의 코드는 생성한 개체들을 지역 변수에 저장하기 때문에 함수의 실행이 끝나면 자동으로 제거되어 스냅샷을 찍어도 개체를 확인할 수 없습니다.
따라서 fnFixedProp() 함수 및 fnRandomProp() 함수 정의에서 array 변수의 선언을 다음과 같이 변경하여 전역 변수로 변경합니다.
(새 창에서 보기)
...
/**
* @description 미리 지정된 속성을 가진 개체를 지정한 개수만큼 생성합니다.
*/
function fnFixedProp() {
var loopCount = document.getElementById("txtLoopCount").value;
console.log("Fixed Property: loopCount-%s", loopCount);
var startTimestamp = (new Date()).getTime();
/* var */ array = [];
... 중략 ...
}
/**
* @description 임의의 이름으로 속성을 매번 추가하여 지정한 개수만큼 개체를 생성합니다.
*/
function fnRandomProp() {
var loopCount = document.getElementById("txtLoopCount").value;
console.log("Random Property: loopCount-%s", loopCount);
var startTimestamp = (new Date()).getTime();
/* var */ array = [];
... 중략 ...
}
...
그리고 지금과 같은 경우에는 너무 많은 개체를 생성해봐야 메모리 힙 스냅샷에서 확인하는 작업만 불편하므로 이번에는 각각 10회 정도씩만 반복해도 문제가 없을 것 같습니다.
다음은 그 결과를 살펴보기 편하게 편집한 모습입니다.
좌측이 fnFixedProp() 함수의 테스트 결과이고 우측이 fnRandomProp() 함수의 테스트 결과입니다.
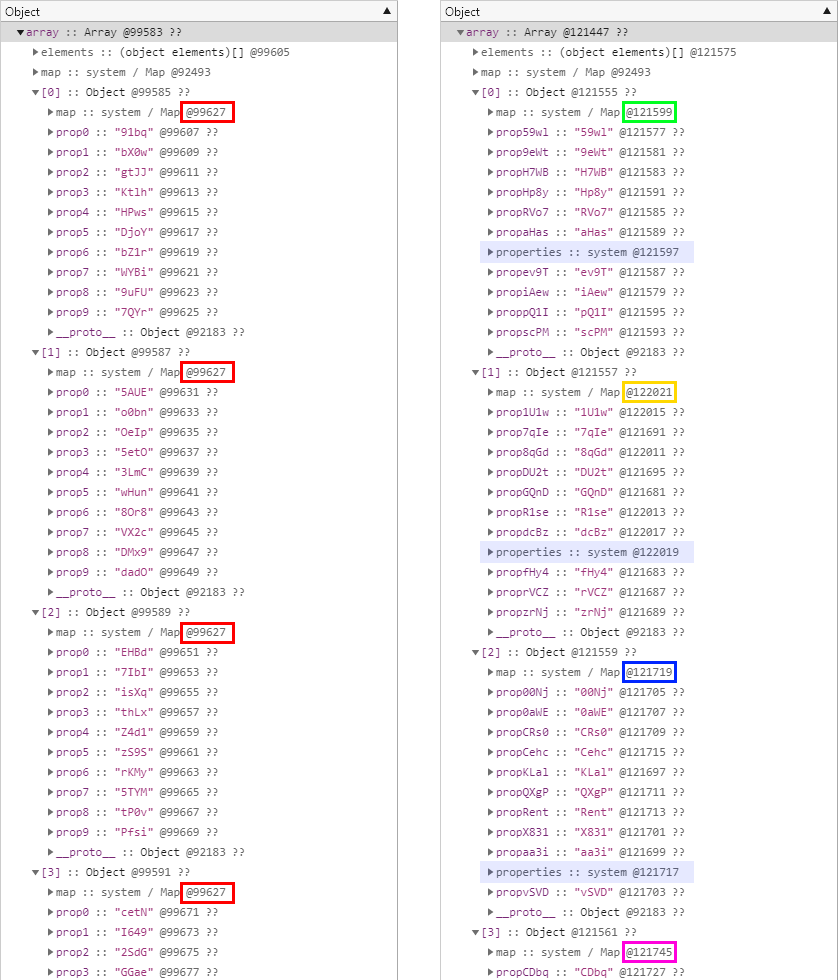
직접 확인할 수 있는 것처럼, 개체의 속성이 항상 같은 이름 및 같은 순서로 미리 정의된 fnFixedProp() 함수가 생성하는 개체들의 히든 클래스는 반복 회수와 상관없이 항상 동일합니다.
반면 런타임에 동적으로 속성 이름과 순서가 결정되는 fnRandomProp() 함수가 생성하는 개체들의 히든 클래스는 개체마다 모두 다릅니다.
혹시라도 우연히 모든 속성 이름과 순서가 동일한 두 개 이상의 개체가 존재한다면 같은 히든 클래스를 참조할 수도 있겠지만 이는 현실적으로는 거의 불가능한 얘기입니다.
그리고 이 캡처만으로는 확인이 어렵지만 fnRandomProp() 함수에서 생성되는 개체의 경우, 단지 개체 하나당 히든 클래스가 달라지는 것뿐만 아니라 실은 매번 속성이 동적으로 추가될 때마다 히든 클래스에 변화가 발생합니다.
이번 섹션에서 _position2 개체에 z라는 이름의 속성을 추가하고 살펴봤던 사항들을 다시 떠올려보시기 바랍니다.
참고로 캡처의 우측 결과를 자세히 살펴보면 본문에서는 언급하지 않았던 properties라는 필드가 눈에 띄는데 이에 대한 내용은 다음 글에서 상세히 살펴보도록 하겠습니다.
인라인 캐싱(Inline caching)
인라인 캐싱을 설명하기에 앞서 지금까지 살펴본 최적화 기법들을 간단히 정리해보겠습니다. 먼저 인라이닝을 통해서 특정 조건을 만족하는 함수들의 호출 과정이 상대적으로 단순하게 정리되며 이로 인해 나름의 성능 개선이 이루어짐을 알게 되었습니다. 또한 V8 엔진이 자체적으로 속성 관련 정보를 담고 있는 히든 클래스를 생성하여 적극적으로 관리한다는 사실도 알게 되었습니다. 비록 실제 업무 수준에서 히든 클래스와 관련하여 발생하는 다양한 사례들을 충분히 살펴보지는 못했지만 히든 클래스가 V8 엔진의 여러 최적화 기법에서 중요한 요소로 자리 잡고 있다는 사실까지는 파악할 수 있었습니다.
그러나 이 두 가지 최적화 기법만으로 본문의 서두에서 예제를 통해 살펴본 것과 같은 상당한 성능 향상이 발생하는 이유를 설명하기에는 어쩐지 부족해 보입니다. 인라이닝으로 인한 성능 개선은 그렇게 결정적이지 않아 보이고 히든 클래스가 중요하다는 점은 알겠는데 왜, 어떻게 중요한지는 잘 이해가 가지 않습니다. 특히 히든 클래스 자체만 놓고 보면 오히려 메모리만 더 많이 사용하고 관리에 필요한 비용만 증가하는 듯 보입니다.
이런 의구심이 드는 것도 당연한 게 지금까지는 히든 클래스로 관련 정보를 취합하는 과정만 설명하고 정작 취합한 정보를 활용하는 방법은 살펴보지 않았기 때문입니다. 열심히 정보를 모으는 이유는 당연히 어딘가에 활용하기 위함입니다. 이제 수집된 정보가 성능 향상에 활용되는 방식을 살펴봐야 할 차례입니다. 그럼 인라인 캐싱에 관해서 간단히 살펴보도록 하겠습니다.
어떤 개체의 속성을 대상으로 값을 읽고 쓰기 위해서는 당연히 먼저 해당 속성에 접근해야 합니다. 만약 사용 중인 동적 언어가 아무런 최적화 기법도 사용하지 않는다면 매번 속성들을 뒤져보는 방법 외에는 다른 선택지가 없으며 이를 동적 조회(Dynamic Lookup)라고 합니다. 언어에 따라 조금씩 다르기는 하지만 동적 조회는 상속 구조 전반을 살펴봐야 하므로 상당한 고비용의 작업이 될 수도 있습니다. 가령 JavaScript에서는 개체 자체에서 지정한 속성을 찾을 수 없는 경우 심하면 프로토타입까지 거슬러 올라가게 됩니다.
이런 문제점을 개선하기 위해서 V8 엔진에서 도입한 기능이 히든 클래스지만 여전히 히든 클래스라도 뒤져봐야 한다는 점은 변하지 않습니다.
그래서 다시 한 차례 이를 보완하기 위한 기능이 조회 캐시(Lookup caches)입니다.
V8 엔진의 조회 캐시는 일정한 개수(아래 링크의 소스 기준 64개)까지 가장 최근의 속성 조회 결과(히든 클래스의 Descriptor Index)를 개체 형식 및 속성 이름 쌍의 조합으로 저장해둡니다.
이때 조회를 시도한 속성이 존재하지 않더라도 그 결과(상수 kAbsent: -2)를 저장하는데 그래야만 나중에 존재하지도 않는 속성을 처음부터 다시 찾는 수고를 덜 수 있기 때문입니다.
그런 다음, 다시 속성에 접근하려고 시도하면 먼저 조회 캐시부터 찾아보고 캐시에 조회 결과가 누락되어 있는 경우에만 동적 조회를 수행합니다.
조회 캐시는 가비지 컬렉터가 동작하기 전에 초기화되며 제한적인 개수의 속성이 반복적으로 호출되는 형태의 프로그램은 이 조회 캐시만으로도 상당한 성능 향상을 얻을 수 있습니다.
- v8/lookup-cache.h at master | v8/v8
- v8/lookup-cache-inl.h at master | v8/v8
- v8/lookup-cache.cc at master | v8/v8
그러나 여전히 개선의 여지는 남아 있습니다. 조회 캐시를 사용하는 경우 속성에 접근할 때마다 캐시부터 찾아봐야 하기 때문입니다. 이런 비용조차 줄이고 싶다면 어떻게 해야 할까요? 여기까지 생각이 이르고 나면 이제 V8 엔진의 인라인 캐싱에 관한 수많은 문서들이 관용구처럼 매번 얘기하는 설명이 등장할 시점입니다.
일반적으로 코드의 특정 위치에서 어떤 개체의 특정 속성에 접근할 경우 다음번에도 그 위치에서는 다시 해당 형식의 해당 속성에 접근할 확율이 매우 높습니다. 또한 아무리 동적 언어라고 하더라도 본문의 예제처럼 런타임에 개체 형식을 극단적으로 빈번하게 변경하는 경우는 그다지 많지 않습니다. 가령 이런 조건을 만족하는 가장 대표적인 코드 패턴은 다음과 같이 동일한 형식의 개체들을 다수 담고 있는 배열에 대한 루프문일 것입니다.
var list = [{ x: 1 }, { x: 2 }, { x: 3 }, { x: 4 }, { x: 5 }];
function add_one(obj) {
return obj.x + 1;
}
for (var i = 0; i < list.length; i++) {
list[i].x = add_one(list[i]);
}물론 이 가정은 언어의 문법 같은 강제적인 규칙이 아닌 어디까지나 경험에 기반한 확률적인 얘기일 뿐이지만 충분히 검토해볼 만한 수준으로 빈번하게 발생하는 패턴이며, 이는 모든 유형의 캐싱에서 가장 기본적으로 전제되는 조건이기도 합니다. V8 엔진은 동작하는 코드를 프로파일링하고 있다가 특정 조건(잠시 후 다시 살펴봅니다)을 만족하는 이런 패턴의 코드를 발견하면 접근 대상을 조회한 결과, 즉 대상 개체의 히든 클래스 정보와 대상 속성의 오프셋을 아예 호출하는 코드의 바이트코드와 함께 인라인으로 저장해둡니다. 그리고 다음부터는 접근하려는 개체의 히든 클래스와 이 캐싱된 정보를 비교해서 만약 같다면 어떠한 조회도 없이 캐싱된 정보를 이용해서 바로 메모리 주소에 접근합니다.
바로 이 점이 개체를 생성할 때 동일한 속성을 동일한 순서로 (가급적 한 번에) 추가하여 같은 히든 클래스를 유지해야 하는 가장 큰 이유입니다. 그리고 바로 이 기법의 이름이 인라인 캐싱인 이유이기도 합니다. 즉 인라이닝이 호출되는 함수의 본문을 호출하는 위치에 삽입하는 기법이라면 인라인 캐싱은 호출하는 위치에 캐시 정보를 삽입하는 기법입니다. 참고로 V8 엔진의 인라인 캐싱 관련 소스는 다음 경로에서 살펴볼 수 있습니다.
당연한 얘기지만 모든 상황에서 아무런 코드나 인라인 캐싱되는 것은 아닙니다.
가장 중요한 조건은 속성에 대한 접근 횟수입니다.
V8 엔진의 인라인 캐시에는 내부적으로 상태 및 전환 표시(Transition Mark)라는 개념이 존재합니다.
여기서 전환 표시는 D8 등의 추적 로그에 LoadIC (1->P) at ...와 같은 형태로 출력되는 코드성 정보입니다.
(아래 링크의 코드 시작 부분을 참고하시기 바랍니다.)
어떤 속성에 처음 접근하면 인라인 캐시의 최초 상태는 UNINITIALIZED(0)이며, 이 첫 번째 접근으로 인해서 PREMONOMORPHIC(.) 상태로 전환됩니다.
그러나 아직 인라인 캐싱이 설정된 상태는 아닙니다.
다시 두 번째로 속성에 접근하면 이번에는 MONOMORPHIC(1) 상태로 전환되고, 다시 세 번째 접근부터는 MONOMORPHIC(1) 상태가 지속되어 인라인 캐싱이 적용됩니다.
이 과정 중에 MONOMORPHIC(1) 상태가 유지되기 위해서 필요한 한 가지 전제조건은 히든 클래스가 동일해야만 한다는 것입니다.
노트
인라인 캐시의 상태 중 PREMONOMORPHIC(.)의 경우 소스를 확인해봐도 상태와 전환 표시에 대한 정의를 찾을 수 없습니다.
그저 'pre-monomorphic'라는 주석의 문구를 통해서 해당 개념이 존재한다는 정도만 확인할 수 있었습니다.
그러나 많은 문서에서 이 상태를 언급하고 있기도 하고 설명의 편의를 위해서도 해당 상태에 대한 용어가 필요해서 그대로 차용했으므로 참고하시기 바랍니다.
그렇다면 다음 코드와 같이 인라인 캐싱이 적용되다가 중간에 접근하는 개체의 형식이 변경될 경우 인라인 캐싱은 그대로 중단되는 것일까요? 일반적으로 그렇게 알고 계신 분들이 많지만 사실은 그렇지 않습니다. 물론 동일한 형식을 유지하는 경우에 가장 빠른 속도를 얻을 수 있지만, 그렇다고 개체 몇 개의 형식이 다르다고 해서 캐시 전체를 포기하는 것은 상식적으로 생각해봐도 너무 비효율적입니다.
var list = [{ x: 1 }, { x: 2 }, { x: 3 }, { x: 4 }, { x: 5 }, ... 중략 ..., { x: 100, y: "oops!" }, { x: 101 }];
function add_one(obj) {
return obj.x + 1;
}
for (var i = 0; i < list.length; i++) {
list[i].x = add_one(list[i]);
}
대신 V8 엔진은 인라인 캐시의 상태를 POLYMORPHIC(P)으로 전환하고 소규모 스텁(Stub)에서 새로운 개체 형식에 대한 접근 정보를 함께 관리하는데 이를 폴리모픽/다형성 인라인 캐싱(Polymorphic inline caching)이라고 합니다.
그러나 폴리모픽 인라인 캐싱이라고 해서 무제한으로 많은 수의 캐싱 정보를 관리하는 것은 아닙니다.
아래 링크의 소스를 살펴보면 DEFINE_INT(max_polymorphic_map_count, 4, "maximum number of maps to track in POLYMORPHIC state")와 같은 정의를 통해서 유지 가능한 캐싱 정보를 최대 4개로 제한하고 있습니다.
(편의를 위해 원본 코드에서 줄바꿈을 제거했습니다.)
마지막으로 접근하는 개체 형식이 4개를 넘으면 인라인 캐시의 상태가 MEGAMORPHIC(N)으로 전환되어 메가로모픽 인라인 캐싱(Megamorphic Inline Caching)의 형태로 동작하게 됩니다.
이 상태에서는 고정된 크기의 공유되는 대규모 전역 스텁(Stub)에서 캐싱 정보가 관리되며 속도는 당연히 가장 느립니다.
지금까지 V8 엔진의 인라인 캐싱에 관한 전반적인 흐름을 간단하게 살펴봤습니다. 이번 섹션에서 전달하고자 하는 바는 단순합니다. 메가로모픽 인라인 캐싱보다 폴리모픽 인라인 캐싱이 더 빠르고, 폴리모픽 인라인 캐싱보다는 모노모픽 인라인 캐싱이 훨씬 더 빠릅니다. 따라서 가급적 모노모픽 인라인 캐싱 상태를 유지해야 합니다. 이를 위해서 웹 클라이언트 프로그래머가 준비해야 할 일은 단지 최대한 히든 클래스를 동일하게 유지하는 것 뿐입니다.
이번 섹션은 제 역량을 다소 넘어서는 내용을 담고 있으며 본문의 시리즈 범위도 상당히 벗어나 있습니다. 최대한 쉽게 풀어서 전달하기 위해 노력했으나 오히려 왜곡하거나 더 혼란스럽게 만들었을 수도 있다고 생각합니다. 인라인 캐싱에 대한 보다 자세한 정보는 다음의 문서들을 참고하시기 바랍니다.
- Inline caching | Wikipedia
- learning-v8/README.md at master | danbev/learning-v8
- Mastering JavaScript high performance | Marc Radziwill blog
- JavaScript engine fundamentals: Shapes and Inline Caches | Mathias Bynens
- 자바스크립트 엔진의 최적화 기법 (2) - Hidden class, Inline Caching | TOAST Meetup
D8 추적 로그로 인라인 캐싱 전환 추이 살펴보기
본문을 마무리하기 전에 인라인 캐싱에 대한 이해를 돕기 위해서 D8의 추적 로그를 이용해서 상태 전환 추이를 한 번 살펴보도록 하겠습니다.
다만 여기에서는 V8 엔진의 소스를 다운로드 받고 컴파일하는 방법은 다루지 않습니다.
이에 관해서는 기회가 될 때 다른 글로 정리해보도록 하겠습니다.
인라이닝 섹션에서 설명했던 실행 파일의 PE 헤더를 변경한 Chromium Edge를 활용하지 않고 D8을 사용하는 이유는 인라인 캐싱의 추적 로그를 기록하는데 필요한 --trace-ic 플래그가 해당 방식에서는 잘 동작하지 않기 때문입니다.
인라인 캐싱 추적 로그를 살펴보기 위해서 사용할 코드는 바로 위에서 살펴봤던 코드를 다음과 같이 약간 변형한 코드입니다.
본문의 예제 HTML 파일은 히든 클래스의 구성 형태 차이를 보여주기 위한 목적에 집중하고 있고 DOM 요소에 접근하기도 해서 이번 테스트의 용도로는 그리 적합하지 않습니다.
참고로 아래 코드에서 기존 코드의 루프문을 start() 함수로 한 번 더 감싼 이유는 속성의 접근 횟수뿐만 아니라 호출하는 코드의 실행 횟수도 V8 엔진이 최적화 대상을 선택할 때 판단의 근거가 되는 중요한 요소이기 때문입니다.
// 1) for MONOMORPHIC(1)
var list = [{ x: 1 }, { x: 2 }, { x: 3 }, { x: 4 }, { x: 5 }];
// 2) for POLYMORPHIC(P)
/*
var list = [{ x: 1 }, { x: 2 }, { x: 3 }, { x: 4 }, { x: 5 }, { x: 6, y: "oops!" }];
*/
function add_one(obj) {
return obj.x + 1;
}
function start(count) {
for (var loop = 0; loop < count; loop++) {
for (var i = 0; i < list.length; i++) {
list[i].x = add_one(list[i]);
}
}
}
start(1000);
이 코드를 V8 엔진의 소스를 빌드하여 생성한 d8.exe 파일과 같은 위치에 test.js 등의 이름으로 저장합니다.
그리고 명령 프롬프트에서 다음과 같은 명령을 입력하여 먼저 첫 번째 배열을 대상으로 추적 로그를 얻습니다.
그러면 동일한 폴더에 v8.log라는 추적 로그 파일이 생성되는데 아직 테스트를 한 번 더 수행해야 하므로 일단 파일명을 v8_mo.log 등으로 변경해둡니다.
d8 --trace-ic test.js
테스트 코드의 주석을 변경하여 같은 방식으로 두 번째 배열을 대상으로 추적 로그를 얻습니다.
이번에는 파일 이름을 v8_po.log 등으로 변경해둡니다.
그러나 이런 방식으로 얻은 두 개의 추적 로그 파일은 테스트 코드의 분량이 그리 많지 않음에도 불구하고 일련의 로그들이 대량으로 장황하게 기록되어 있기 때문에 일목 요연하게 비교하기가 어렵습니다.
그래서 보통은 git의 fetch 명령을 실행한 폴더를 기준으로 .\v8\tools 폴더에 위치한 ic-processor 도구를 사용하여 한 차례 정리 및 취합해야 합니다.
그런데 문제는 Windows 환경에서 이 도구가 잘 동작하지 않는다는 점입니다.
하지만 대신 같은 폴더에 위치한 ic-explorer.html 파일을 활용해서 보다 시각적으로 비교가 가능합니다.
웹 브라우저 두 개에서 ic-explorer.html 파일을 실행하고 D8로 생성한 추적 로그 파일들을 각각 선택합니다.
그런 다음 Group-Key 드롭다운에서 state 항목을 선택합니다.
다음은 그 결과를 비교하기 쉽게 정리한 모습입니다.
좌측이 첫 번째 배열에 대한 결과이고 우측이 두 번째 배열에 대한 결과입니다.
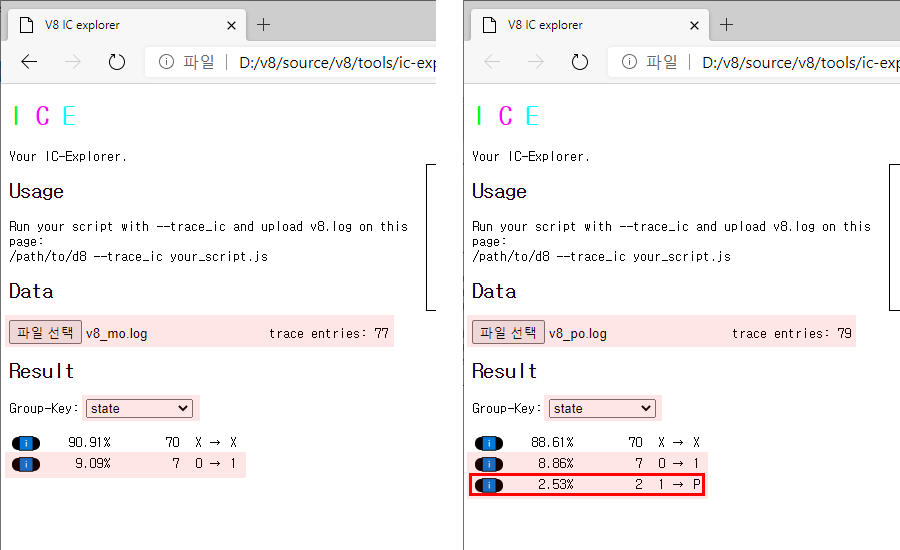
모든 개체의 히든 클래스가 동일한 첫 번째 배열의 추적 로그를 보여주는 좌측의 결과에는 MONOMORPHIC 상태(전환 표시: 0 → 1)의 인라인 캐시만 존재합니다.
반면 두 형식의 개체, 즉 두 종류의 히든 클래스가 공존하는 두 번째 배열의 추적 로그를 보여주는 우측의 결과에는 POLYMORPHIC 상태(전환 표시: 1 → P)의 인라인 캐시가 동시에 존재합니다.
엄밀히 말하자면 0 상태에서 1 상태로, 그리고 다시 1 상태에서 P 상태로 전환되는 과정을 보여주고 있는 셈입니다.
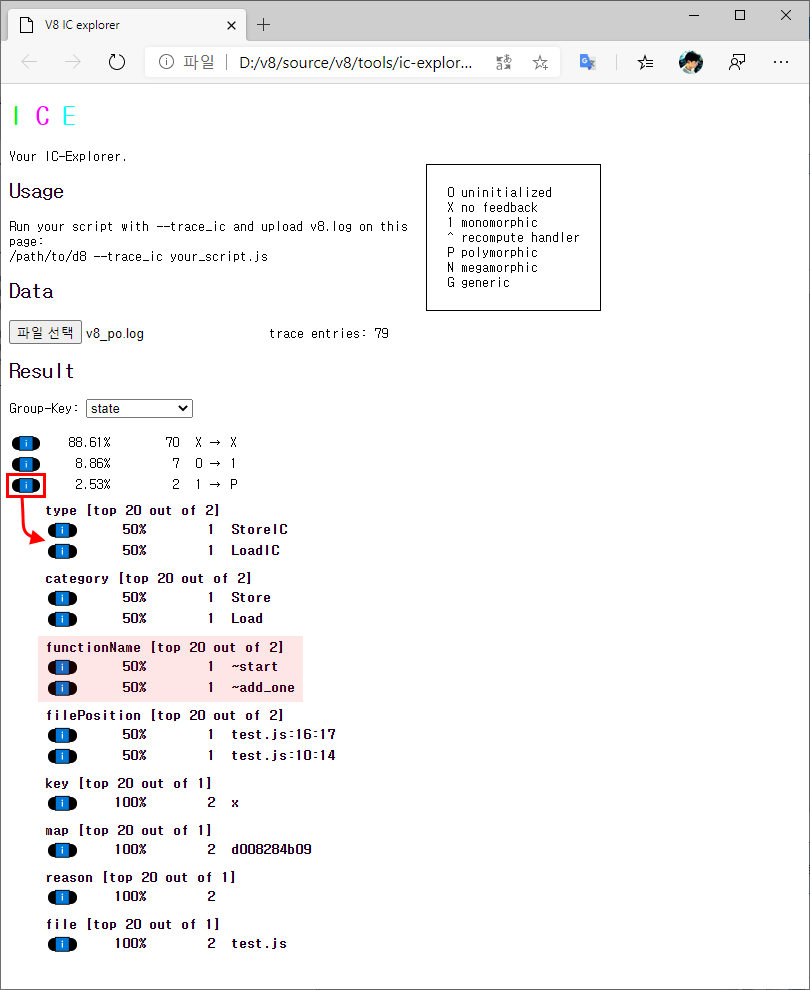
각 정보 표시줄 좌측의 i 문자의 아이콘을 클릭하면 다음과 같이 순차적으로 세부 정보를 살펴볼 수 있습니다.
가령 POLYMORPHIC 상태 표시줄을 확장해보면 인라인 캐싱된 각 함수들을 확인할 수 있습니다.
정리
본문에서는 Chromium 계열의 브라우저가 메모리 힙 스냅샷을 통해서 제공하는 정보를 보다 잘 이해하기 위해서 V8 엔진의 동작 방식을 간단하게 살펴봤습니다. V8 엔진의 실행 파이프라인 및 인라이닝, 히든 클래스, 인라인 캐싱 같은 최적화 기법에 대해서도 알아보고 명령줄 스위치를 활용하여 V8 엔진의 관련 추적 로그를 기록하여 검토해봤습니다.
이어지는 글에서는 메모리 힙 스냅샷을 활용해서 V8 엔진이 개체를 관리하는 방법에 대해 조금 더 자세히 살펴보도록 하겠습니다.
- IE11을 이용한 JavaScript 디버깅 01, F12 개발자 도구 콘솔 창 2019-01-01 08:00
- IE11을 이용한 JavaScript 디버깅 02, console 개체 2019-01-08 08:00
- IE11을 이용한 JavaScript 디버깅 03, F12 개발자 도구 DOM 탐색기 창 Part 1 2019-01-15 08:00
- IE11을 이용한 JavaScript 디버깅 04, F12 개발자 도구 DOM 탐색기 창 Part 2 2019-01-22 08:00
- IE11을 이용한 JavaScript 디버깅 05, F12 개발자 도구 디버거 창 Part 1 2019-01-29 08:00
- IE11을 이용한 JavaScript 디버깅 06, F12 개발자 도구 디버거 창 Part 2 2019-02-12 08:00
- IE11을 이용한 JavaScript 디버깅 07, F12 개발자 도구 디버거 창 Part 3 2019-02-19 08:00
- IE11을 이용한 JavaScript 디버깅 08, F12 개발자 도구 디버거 창 Part 4 2019-02-26 08:00
- IE11을 이용한 JavaScript 디버깅 09, F12 개발자 도구 디버거 창 Part 5 2019-03-05 08:00
- IE11을 이용한 JavaScript 디버깅 10, F12 개발자 도구 네트워크 창 Part 1 2019-03-19 08:00
- IE11 및 Chromium Edge에서 메모리 힙 스냅샷 찍기 2020-02-25 08:00
- IE11 및 Chromium Edge에서 메모리 힙 스냅샷 비교하기 2020-03-10 08:00
- Chromium Edge의 메모리 힙 스냅샷 분석을 위한 V8 엔진의 이해 1. 2020-03-24 08:00
- Chromium Edge의 메모리 힙 스냅샷 분석을 위한 V8 엔진의 이해 2. 2020-04-07 08:00
- Visual Studio Community로 V8 엔진 다운로드 및 빌드하고 간단히 살펴보기 2020-04-21 08:00
- IE11 및 Chromium Edge에서 가상의 메모리 누수 상황 재현 및 해결하기 2020-05-05 08:00




